bebert73
-
Compteur de contenus
8 -
Inscription
-
Dernière visite
À propos de bebert73
.png.96b3b3865e7602c8e02642dcb636f80b.png)
Visiteurs récents du profil
905 visualisations du profil
bebert73's Achievements
")




-
Salut @.Shad. C'est bien du bridge (et je n'utilise pas les variables HOSTFS). De tout de façon j'ai mis en place le SNMP pour avoir les infos complémentaire mais de base il y a deja pas mal de chose. @oracle7 Si tu peux me partager ta config SNMP pour SRM (avec les mibs) je suis preneur :).
-
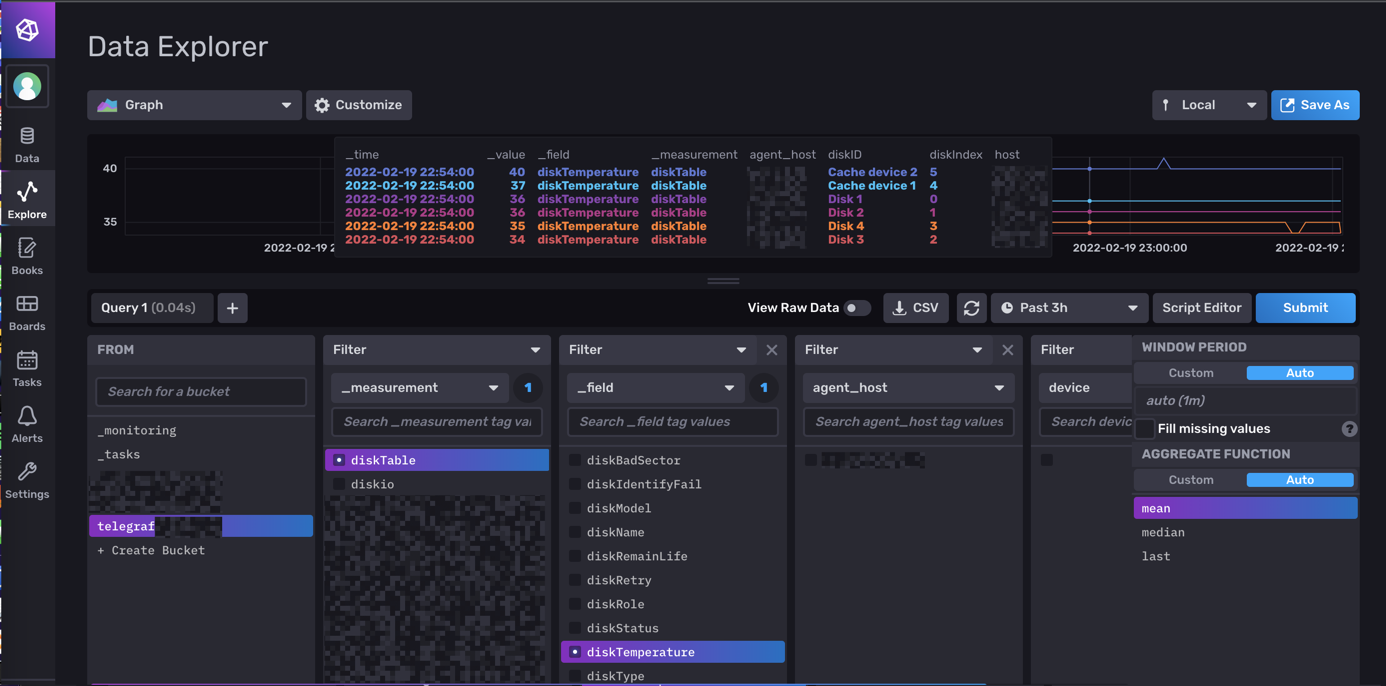
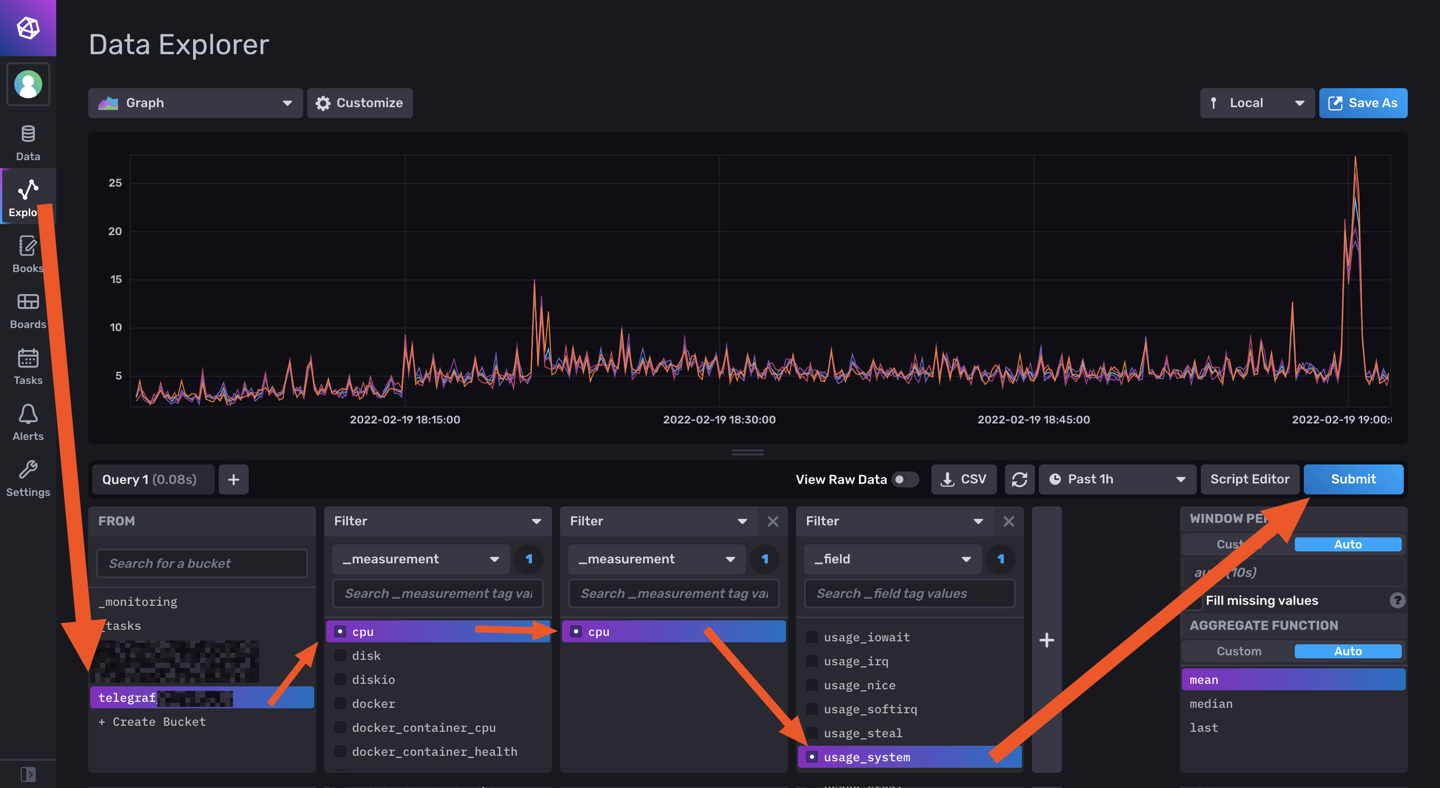
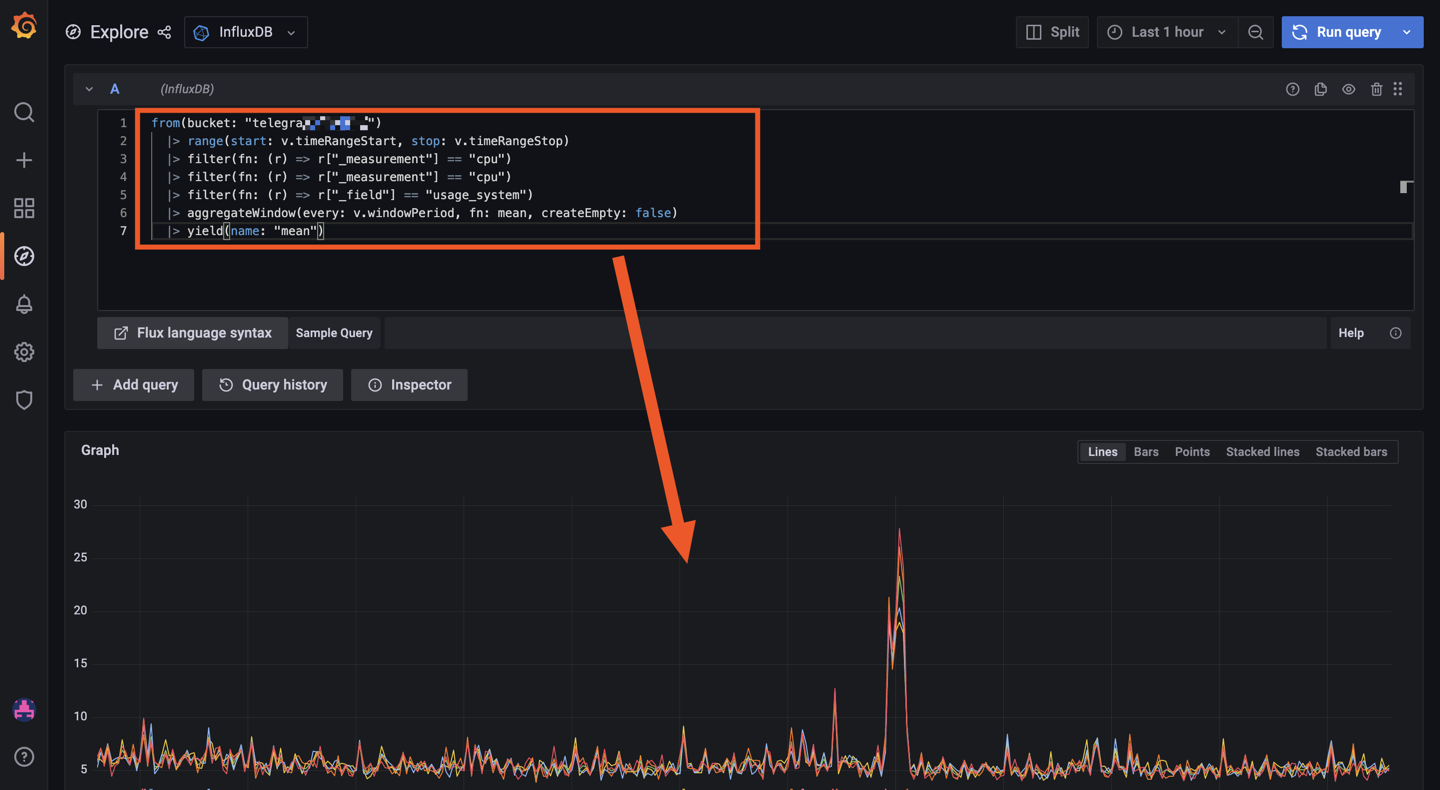
Salut @.Shad. ! Alors on vas rester sur un mystere car c'est bien fonctionnel (petit comparatif infludb sans SNMP et les data DSM): @MilesTEG1 Je rejoins @.Shad. pour la version actuelle de Influxdb, on peut faire un dashboard mais il n'y a pas de moyen d'extraire les rendus ou de trop modifier le dashboard en profondeur. Par contre le WebUI Influxdb devient indispensable pour fair tes query dans grafana. Je test un peu influxdb 2.x : Le truc qui est vraiment bien pensé c'est les templates : Ce sont des templates Dashboard/Bucket(db)/et config telegraf réunis ! Tu peux mettre en variable le nom de ton bucket aussi comme ça sur un même dashboard, en un click tu change de database (pas facile a expliqué mais bien pensé). Quelques dashbord que j'ai importé en 5 min :
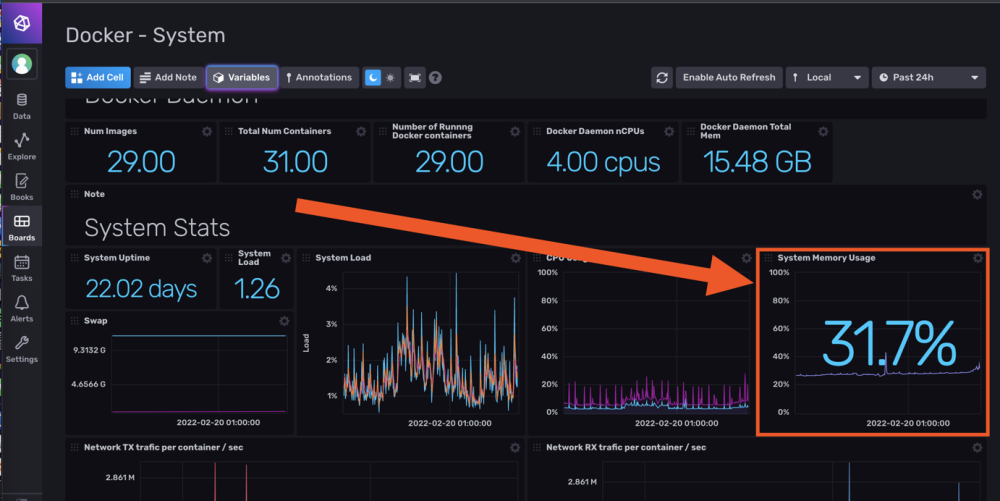
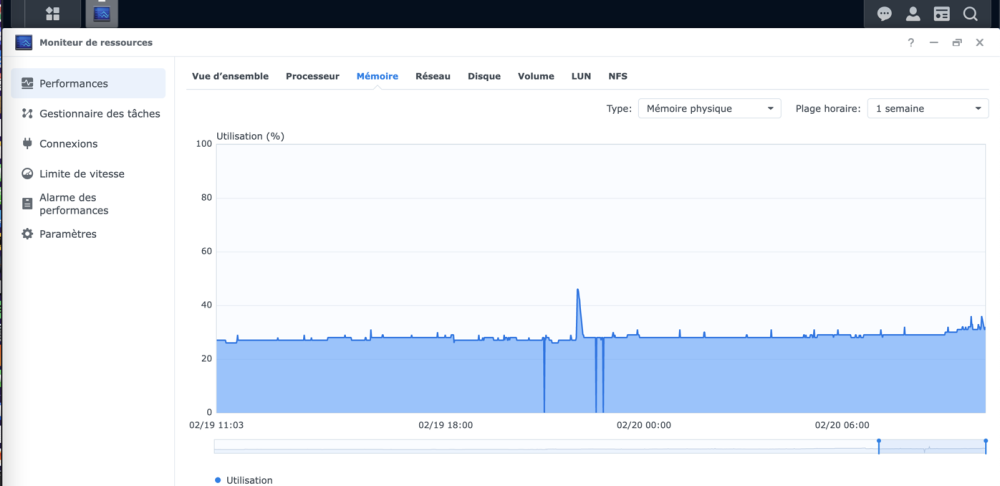
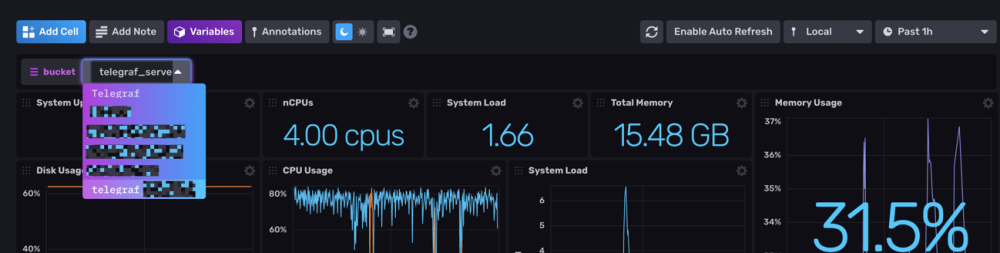
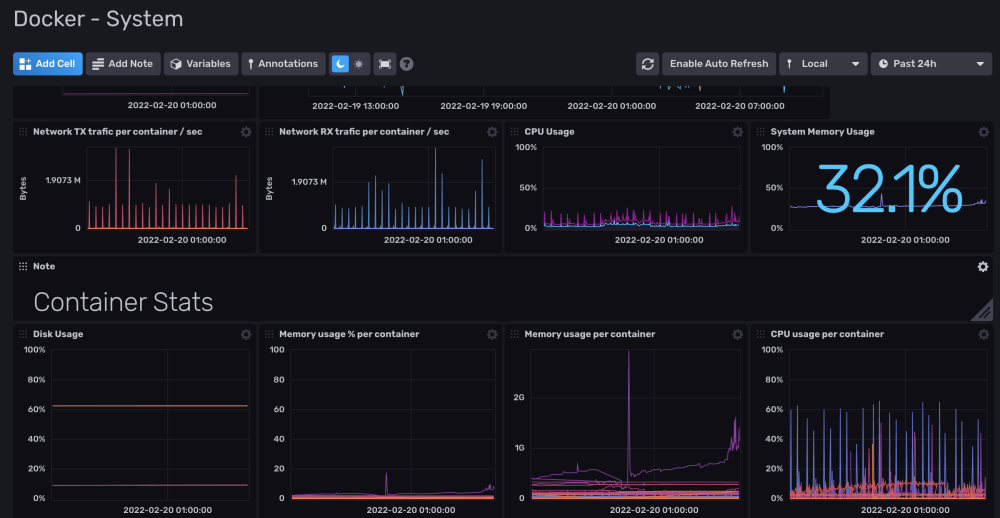
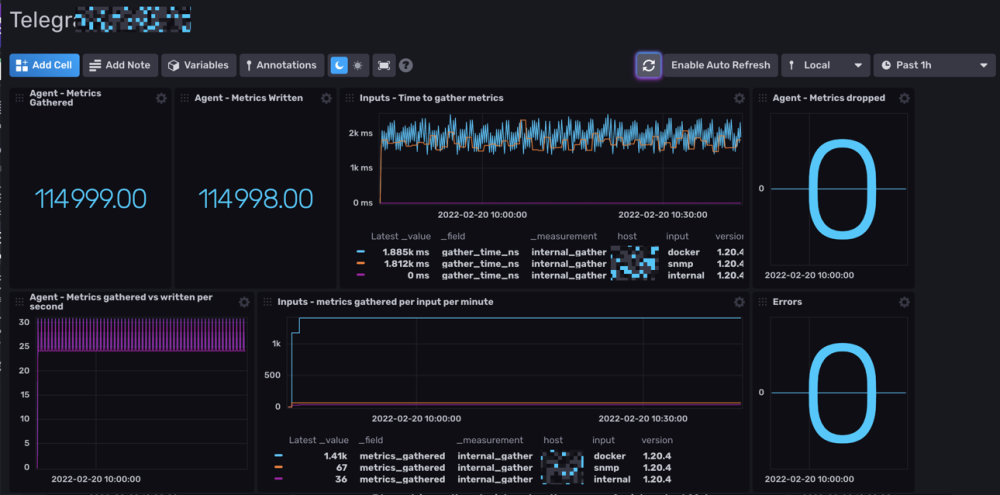
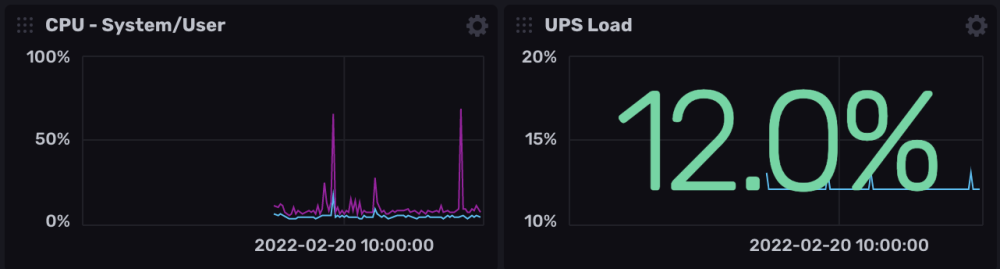
-
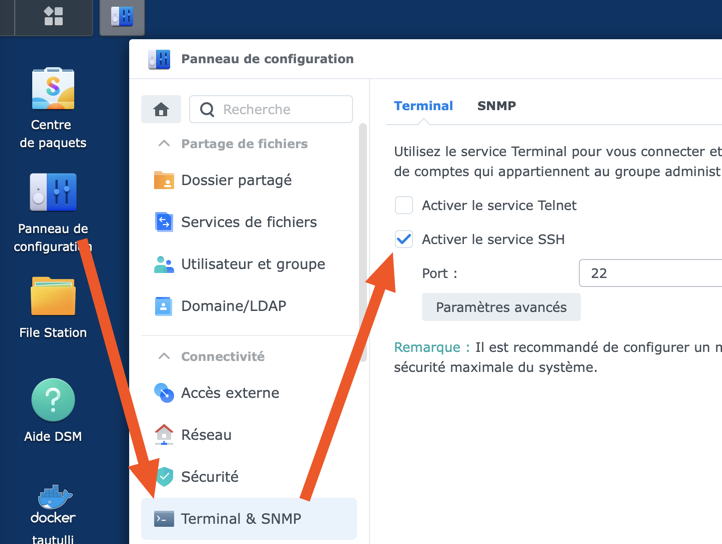
Bon à l'instant T SNMP fonctionne avec telegraf en 1.20.4 en suivant la config SNMP de @.Shad.
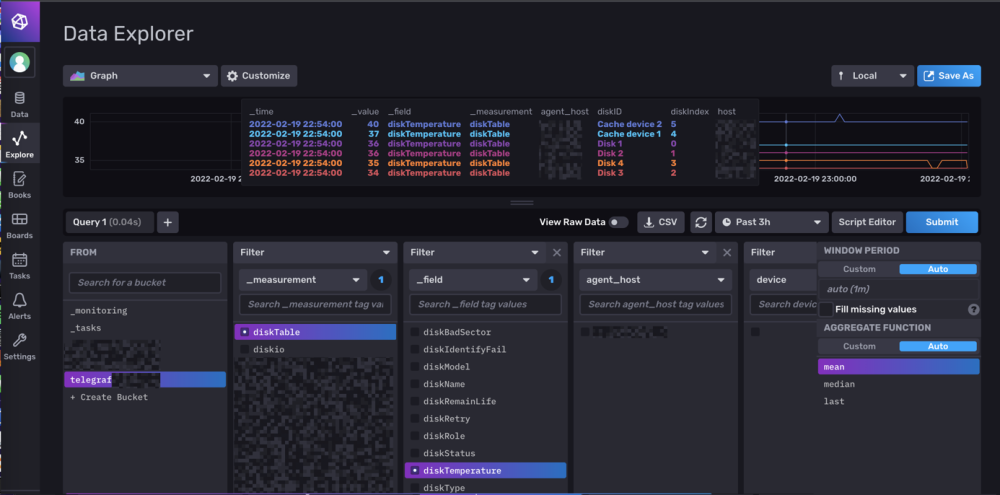
-
Pour la sécurité : Grafana est sensé ne faire que "lire" les datas --> Donc lecture seul Telegraf est sensé écrire --> Lecture/Ecriture Si ton service Grafana est vérolé ou que tu fais des bêtises, l'écriture ne sera pas possible. PS : En vrais dans mes docker je rajoute toujours l'update auto avec watchtower.
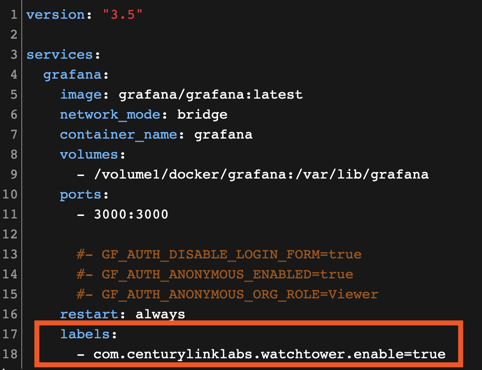
-
j'ai mis à jours le point 8 : Avec influxdb 2.x les autres services ne se connect pas avec des identifiants, mais avec des tokens générés pour chaque besoin/db. On peut générés autant de token que l'ont souhaite en fonction des droits d'acces, c'est plus simple : Token1 : Lecture/ecriture sur telegraf Token2 : Lecture seul sur telegraf Token3 : Lecture/ecriture sur telegraf et jeedom ...
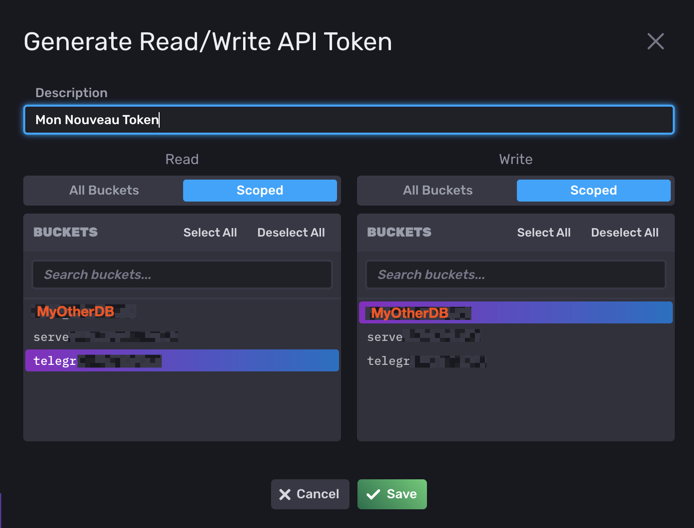
-
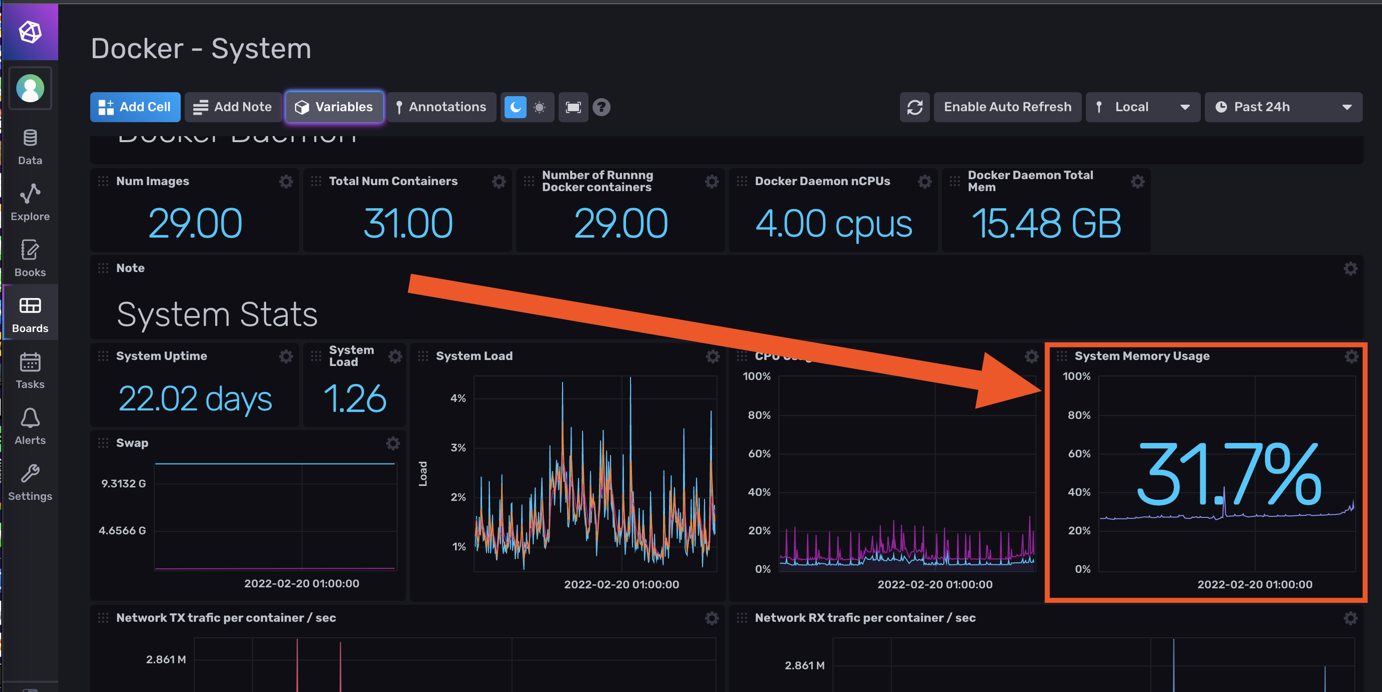
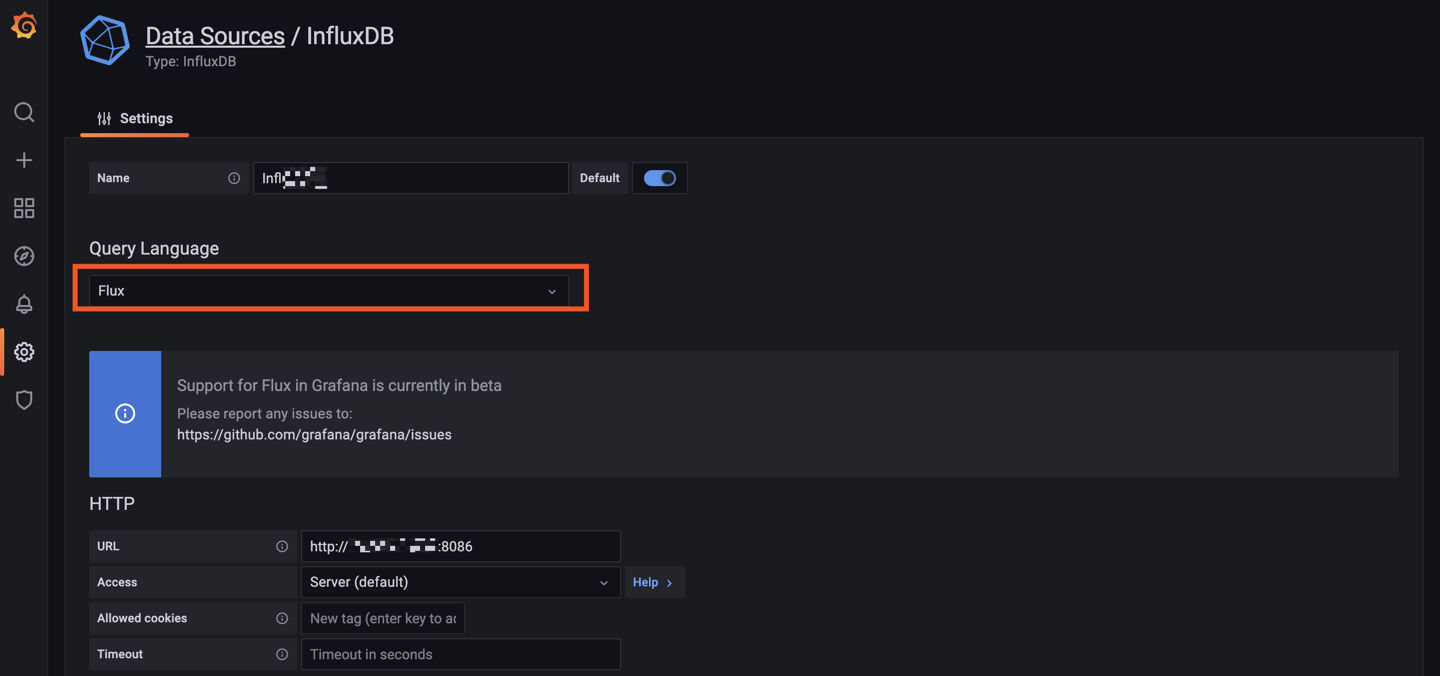
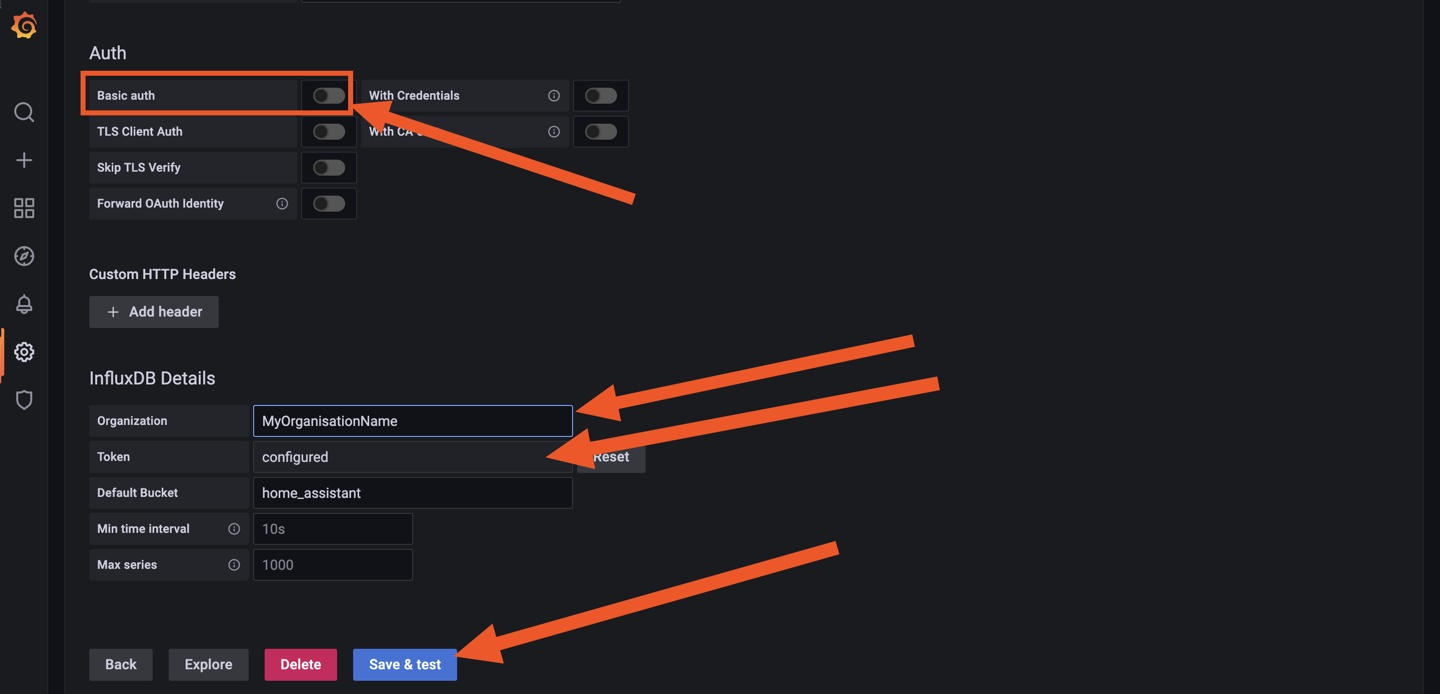
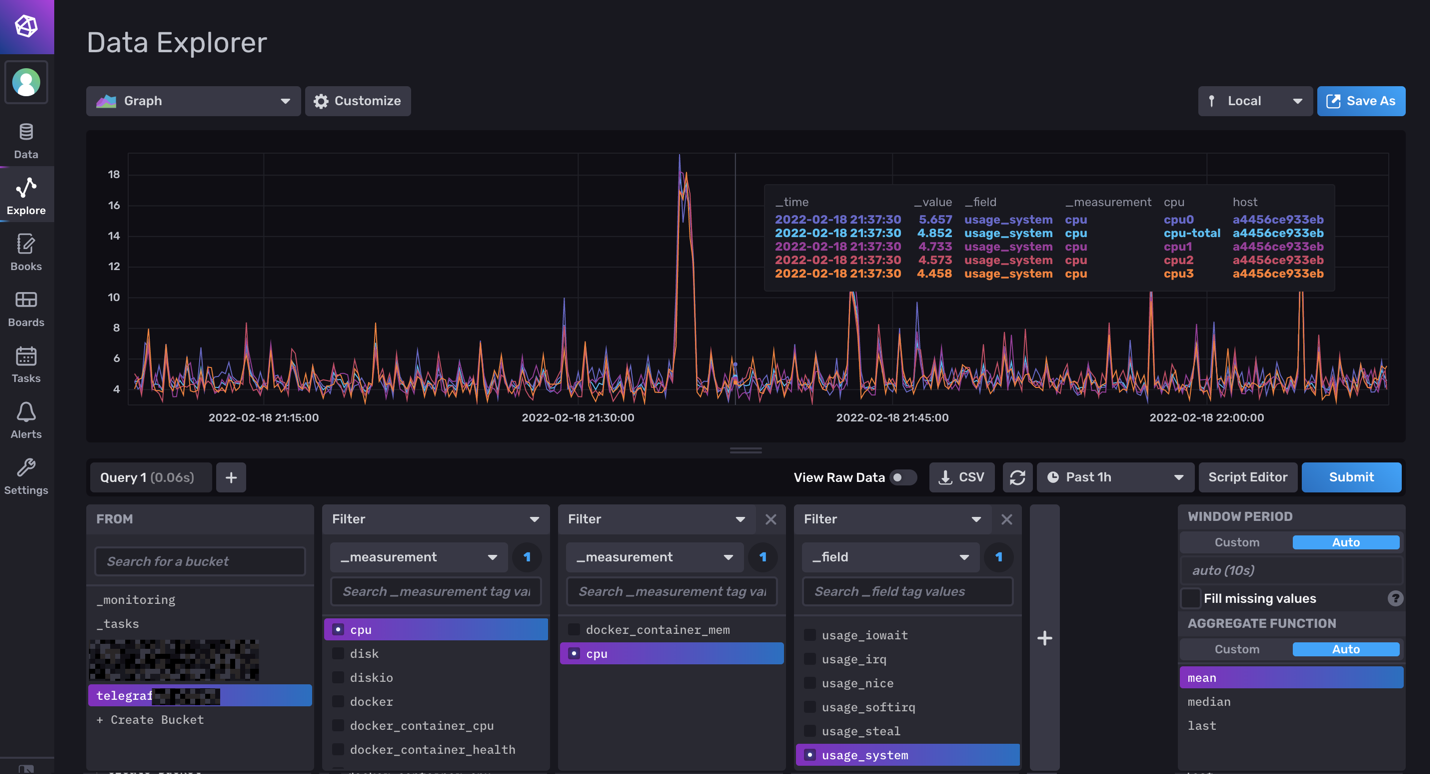
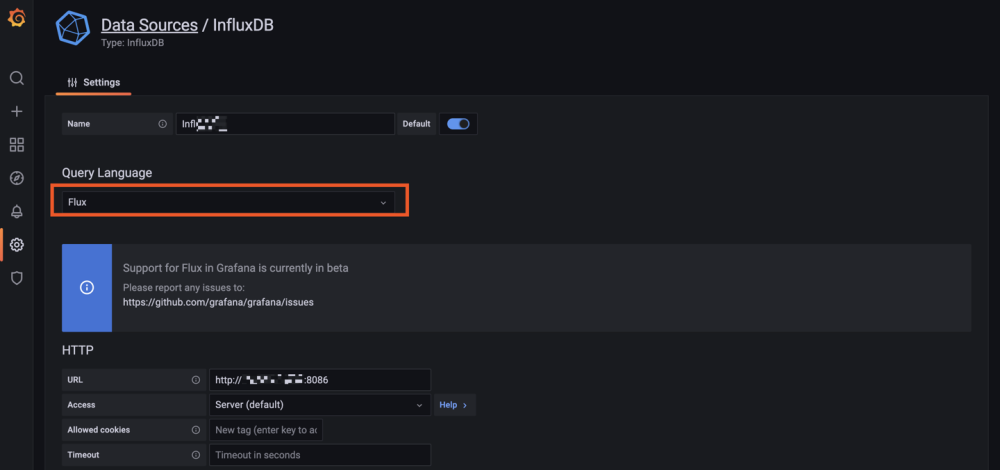
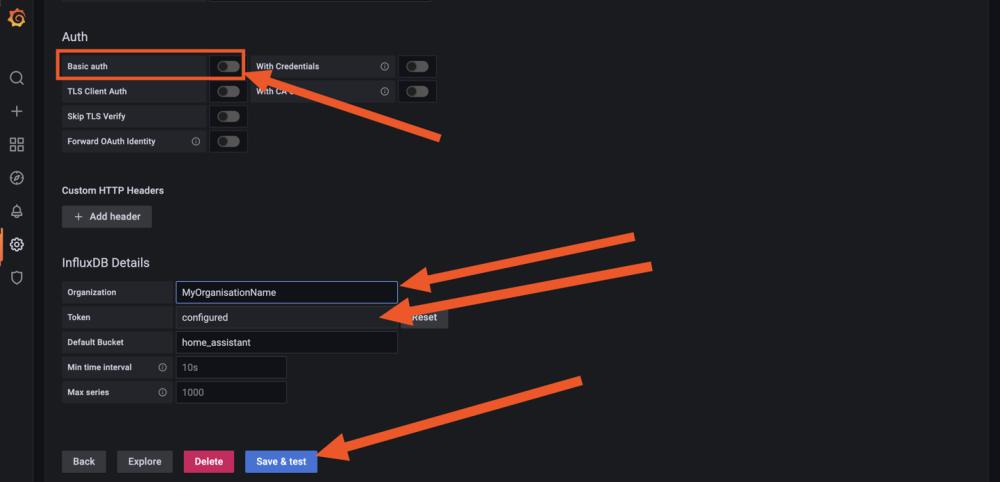
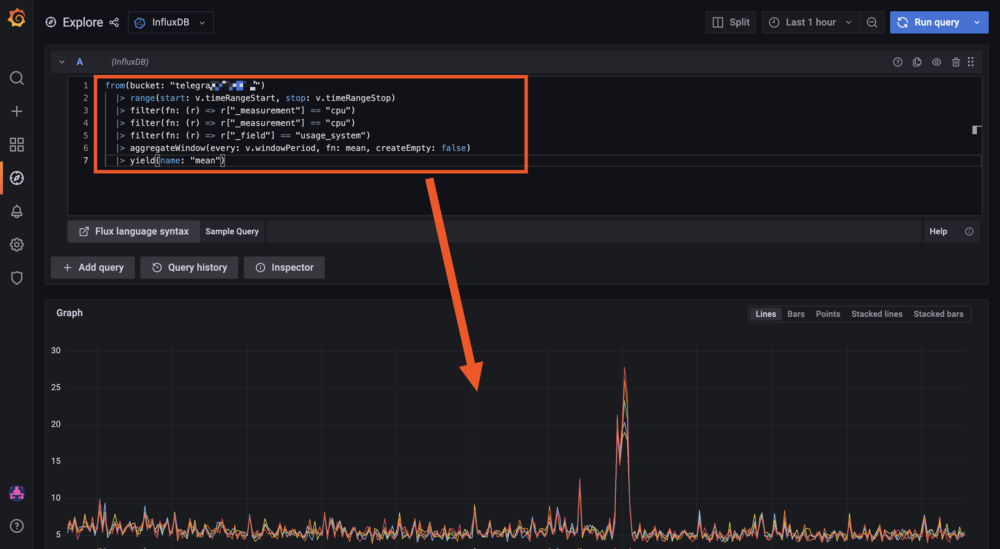
Hello tous, @.Shad. Pas de host ni de privileged sur mon conteneur telegraf, mais j'ai bien les infos du serveur (et pas que le conteneur). Du coup je comprends pas trop... ^^ mais je te laisse regarder ma config pour comprendre le problème. @oracle7 Je fais tout mes dockers via Portainer (en faisant des stacks docker compose). Je te partage mes 3 composes qui fonctionne et ma méthodo que j'ai mis en place. Encore une fois je débute sous docker/influxdb/ect, c'est plus de la bidouille qu'autre chose. Les principales différences que je vois (de 1.8 à 2.x): La connection qui se fait via des tokens avec les autres services (telegraf, grafana,...) Le web UI (tres proche de grafana!, je rejoins le commentaire d'un précédent poste, il veulent tuer grafana). Le language Query qui est passé à Flux (vs SQL ?) Je pense qu'en débutant c'est pas beaucoup plus compliqué que 1.8 . Le Tuto de Bebert (enfin vite fait mais bon... en 10 points quand même et le dernier est primordial) : 1- Les dossiers Créer deux dossier (ici /volume1/docker/influxdb et /volume1/docker/telegraf) en mettant les droits lecture/ecriture à /influxdb à tout le monde (chmod 777) pour le dossier /influxdb et ces sous dossier. Action a faire au choix par terminal ou SSH. Utile lors de la premiere création du docker. Je ne sais pas pourquoi mais des que le docker influxdb est lancé les droits change ... 2- Le Docker InfluxDB version: '3' services: influxdb: image: influxdb:latest container_name: influxdb network_mode: bridge restart: always volumes: # Mount for influxdb data directory and configuration - /volume1/docker/influxdb:/var/lib/influxdb2 - /volume1/docker/influxdb/data:/etc/influxdb2 ports: - MyPort:8086 3-Lancer et configurer influxdb via le webUI sur le port 8086 de votre localhost Suiver les instructions --> User, Organisation, password. MyBucketDBName : Créer un database (Bucket) : Database/Bucket/CreateBucket --> Avec le nom de la db "telegraf" MyToken : Créer un Token pour l'acces r/w à votre db "teelgraf" : Database/Token/CreateToken MyOrganisationID : Copié l'id d'organisation 4-telegraf.conf Dans l'onglet telegraf vous pouvez générer un telegraf.conf partiellement fonctionnel, voici la partie output fonctionnel pour moi en récupérant les 3 variables précédentes MyXXXX : [[outputs.influxdb_v2]] ## The URLs of the InfluxDB cluster nodes. ## ## Multiple URLs can be specified for a single cluster, only ONE of the ## urls will be written to each interval. ## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"] urls = ["http://MyIPAdress:MyPort"] ## Token for authentication. token = "MyToken" ## Organization is the name of the organization you wish to write to; must exist. organization = "MyOrganisationID" ###################. Attention ce n'est pas le nom de l'oragnisation mais sont ID. Disponible dans influxdb webUI User/About. ############ ## Destination bucket to write into. bucket = "MyBucketDBName" ## The value of this tag will be used to determine the bucket. If this ## tag is not set the 'bucket' option is used as the default. # bucket_tag = "" ## If true, the bucket tag will not be added to the metric. # exclude_bucket_tag = false ## Timeout for HTTP messages. # timeout = "5s" ## Additional HTTP headers # http_headers = {"X-Special-Header" = "Special-Value"} ## HTTP Proxy override, if unset values the standard proxy environment ## variables are consulted to determine which proxy, if any, should be used. # http_proxy = "http://corporate.proxy:3128" ## HTTP User-Agent # user_agent = "telegraf" ## Content-Encoding for write request body, can be set to "gzip" to ## compress body or "identity" to apply no encoding. # content_encoding = "gzip" ## Enable or disable uint support for writing uints influxdb 2.0. # influx_uint_support = false ## Optional TLS Config for use on HTTP connections. # tls_ca = "/etc/telegraf/ca.pem" # tls_cert = "/etc/telegraf/cert.pem" # tls_key = "/etc/telegraf/key.pem" ## Use TLS but skip chain & host verification #insecure_skip_verify = false 5-Docker telegraf Perso je l'ai rajouter à mon stack influxdb dans Portainer mais sinon faite un nouveau docker Compose telegraf: image: telegraf:latest container_name: telegraf network_mode: bridge restart: unless-stopped ports: # Optionnel - 8125:8125 # Optionnel - 8092:8092/udp # Optionnel - 8094:8094 # Optionnel volumes: # Mount for influxdb data directory and configuration - /volume1/docker/telegraf/telegraf.conf:/etc/telegraf/telegraf.conf:ro - /var/run/docker.sock:/var/run/docker.sock - /etc/localtime:/etc/localtime:ro - /etc/TZ:/etc/timezone:ro Je ne sais pas si les ports de telegraf sont utiles pour le moment (pas trop le temps de tout regarder et de vous répondre ^^). 6-Vérification des data et fonctionnement des Query : On vérifie si les datas remonte bien (moi j'aime bien regarder les logs des containers via Dozzle). On check dans le webUI de influxdb et on fait son premier "query". Si on click sur Script editor on à le Query (c'est cette forme la que j'utilisera apres dans grafana). 7-On fait un docker Grafana Créer un dossier /volume1/docker/grafana, puis créer le docker (toujours avec un stack de Portainer pour moi): version: "3.5" services: grafana: image: grafana/grafana:latest network_mode: "bridge" container_name: grafana volumes: - /volume1/docker/grafana:/var/lib/grafana ports: - 3000:3000 #- GF_AUTH_DISABLE_LOGIN_FORM=true #- GF_AUTH_ANONYMOUS_ENABLED=true #- GF_AUTH_ANONYMOUS_ORG_ROLE=Viewer restart: always 8- Config grafana : Suivre les instructions sur le webUI (user password ect...) On ajoute une database influx. Attention, QUERY language en Flux ! Attention dans Organization c'est cette fois le Nom de votre Organisation. Le token est un nouveau token créé dans influxdb en lecture seul pour le bucket telegraf. Avec influxdb 2.x les autres services ne se connect pas avec des identifiants, mais avec des tokens générés pour chaque besoin/db. 9-Mon premier graf... Du coup les graphiques sont à base de query en FLUX. 10-Déconnecter internet et aller faire à manger... Je regarderais SNMP plus tard (puis mes autres device a mettre dans telegraf, puis créer un dashboard server/network/docker pour le partage, puis conquérir le monde ...). ++

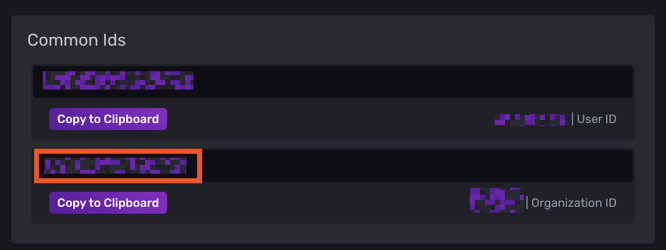


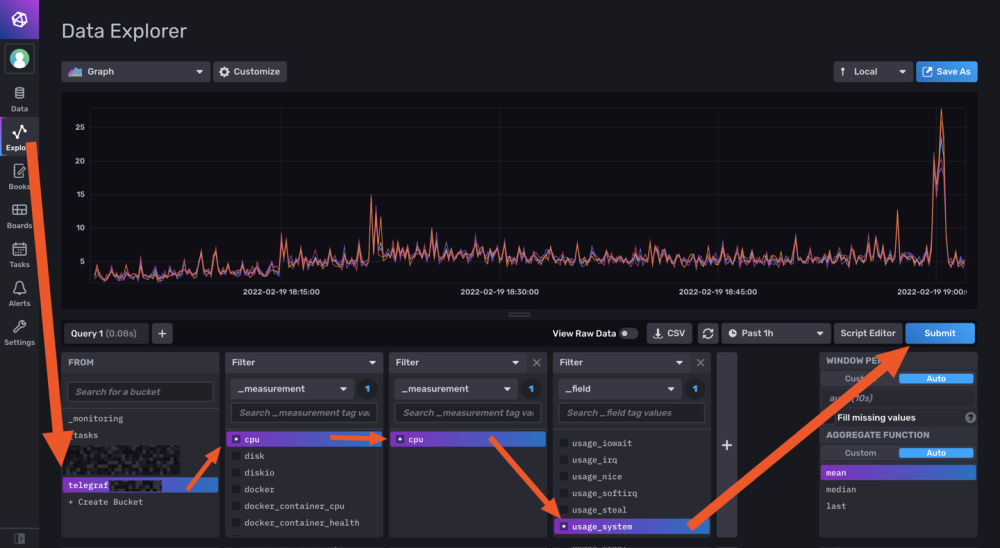
-
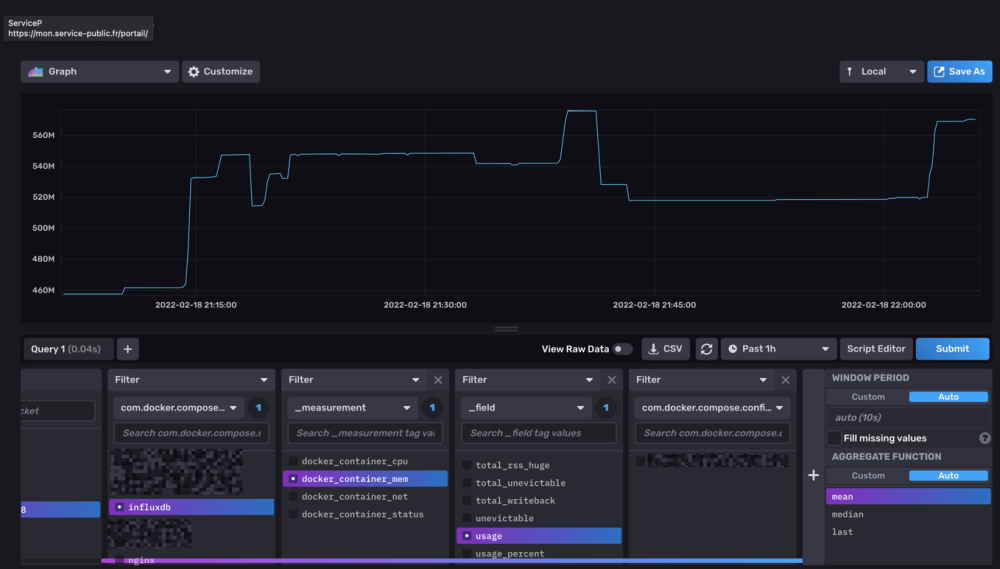
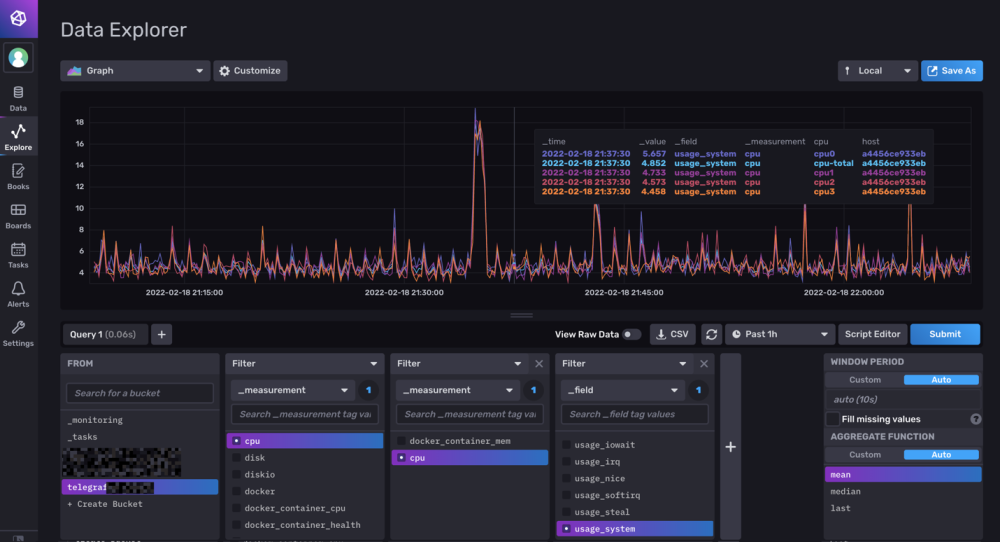
Hello tout le monde. Etant sous dsm7 avec un DS918+, je cherchais a monitorer mon NAS et Docker. @.Shad. Merci pour ton tuto. J'ai essayé... mais beaucoup d'erreur avec la particularité de ta configuration des UserGroups. Je me suis mis au Docker il y à 2-3 mois donc je suis pas encore au top, mais du coup j'ai voulus me lancer dans l'aventure. A l'instant T, j'ai dockerisé Influxdb 2.1.1 et telegraf:latest. Ce que je n'ai pas fait : - Activation de SNMP - Créer un User ou USERGROUP telegraf - Changer les droits de docker.sock Ce que j'ai fait : - Changer les permissions des dossiers influxdb et telegraf utilisé par mes containers - Fait mes propres dockercompose (et tu as été une source d'inspiration). La je m'attaque à Grafana quand j'ai un peu de temps (maintenant que je collect toutes les data du server/docker). Juste pour info une partie de mon fichier telegraf.conf pour la remonté sans SNMP (attention pour influxdb 2.1.1 !!): # Configuration for telegraf agent [agent] ## Default data collection interval for all inputs interval = "10s" ## Rounds collection interval to 'interval' ## ie, if interval="10s" then always collect on :00, :10, :20, etc. round_interval = true ## Telegraf will send metrics to outputs in batches of at most ## metric_batch_size metrics. ## This controls the size of writes that Telegraf sends to output plugins. metric_batch_size = 1000 ## Maximum number of unwritten metrics per output. Increasing this value ## allows for longer periods of output downtime without dropping metrics at the ## cost of higher maximum memory usage. metric_buffer_limit = 10000 ## Collection jitter is used to jitter the collection by a random amount. ## Each plugin will sleep for a random time within jitter before collecting. ## This can be used to avoid many plugins querying things like sysfs at the ## same time, which can have a measurable effect on the system. collection_jitter = "0s" ## Default flushing interval for all outputs. Maximum flush_interval will be ## flush_interval + flush_jitter flush_interval = "10s" ## Jitter the flush interval by a random amount. This is primarily to avoid ## large write spikes for users running a large number of telegraf instances. ## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15s flush_jitter = "0s" ## By default or when set to "0s", precision will be set to the same ## timestamp order as the collection interval, with the maximum being 1s. ## ie, when interval = "10s", precision will be "1s" ## when interval = "250ms", precision will be "1ms" ## Precision will NOT be used for service inputs. It is up to each individual ## service input to set the timestamp at the appropriate precision. ## Valid time units are "ns", "us" (or "µs"), "ms", "s". precision = "" ## Log at debug level. # debug = false ## Log only error level messages. # quiet = false ## Log target controls the destination for logs and can be one of "file", ## "stderr" or, on Windows, "eventlog". When set to "file", the output file ## is determined by the "logfile" setting. # logtarget = "file" ## Name of the file to be logged to when using the "file" logtarget. If set to ## the empty string then logs are written to stderr. # logfile = "" ## The logfile will be rotated after the time interval specified. When set ## to 0 no time based rotation is performed. Logs are rotated only when ## written to, if there is no log activity rotation may be delayed. # logfile_rotation_interval = "0d" ## The logfile will be rotated when it becomes larger than the specified ## size. When set to 0 no size based rotation is performed. # logfile_rotation_max_size = "0MB" ## Maximum number of rotated archives to keep, any older logs are deleted. ## If set to -1, no archives are removed. # logfile_rotation_max_archives = 5 ## Pick a timezone to use when logging or type 'local' for local time. ## Example: America/Chicago # log_with_timezone = "" ## Override default hostname, if empty use os.Hostname() hostname = "" ## If set to true, do no set the "host" tag in the telegraf agent. omit_hostname = false [[outputs.influxdb_v2]] ## The URLs of the InfluxDB cluster nodes. ## ## Multiple URLs can be specified for a single cluster, only ONE of the ## urls will be written to each interval. ## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"] urls = ["http://192.168.1.xxx:9999"] ## Token for authentication. token = "oiqhsx9xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx==" ## Organization is the name of the organization you wish to write to; must exist. organization = "d4xxxxxxxxxxxxxx" ## Destination bucket to write into. bucket = "telegraf_server" ## The value of this tag will be used to determine the bucket. If this ## tag is not set the 'bucket' option is used as the default. # bucket_tag = "" ## If true, the bucket tag will not be added to the metric. # exclude_bucket_tag = false ## Timeout for HTTP messages. # timeout = "5s" ## Additional HTTP headers # http_headers = {"X-Special-Header" = "Special-Value"} ## HTTP Proxy override, if unset values the standard proxy environment ## variables are consulted to determine which proxy, if any, should be used. # http_proxy = "http://corporate.proxy:3128" ## HTTP User-Agent # user_agent = "telegraf" ## Content-Encoding for write request body, can be set to "gzip" to ## compress body or "identity" to apply no encoding. # content_encoding = "gzip" ## Enable or disable uint support for writing uints influxdb 2.0. # influx_uint_support = false ## Optional TLS Config for use on HTTP connections. # tls_ca = "/etc/telegraf/ca.pem" # tls_cert = "/etc/telegraf/cert.pem" # tls_key = "/etc/telegraf/key.pem" ## Use TLS but skip chain & host verification #insecure_skip_verify = false [[inputs.cpu]] ## Whether to report per-cpu stats or not percpu = true ## Whether to report total system cpu stats or not totalcpu = true ## If true, collect raw CPU time metrics collect_cpu_time = false ## If true, compute and report the sum of all non-idle CPU states report_active = false [[inputs.disk]] ## By default stats will be gathered for all mount points. ## Set mount_points will restrict the stats to only the specified mount points. # mount_points = ["/"] ## Ignore mount points by filesystem type. ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"] [[inputs.diskio]] ## By default, telegraf will gather stats for all devices including ## disk partitions. ## Setting devices will restrict the stats to the specified devices. # devices = ["sda", "sdb", "vd*"] ## Uncomment the following line if you need disk serial numbers. # skip_serial_number = false # ## On systems which support it, device metadata can be added in the form of ## tags. ## Currently only Linux is supported via udev properties. You can view ## available properties for a device by running: ## 'udevadm info -q property -n /dev/sda' ## Note: Most, but not all, udev properties can be accessed this way. Properties ## that are currently inaccessible include DEVTYPE, DEVNAME, and DEVPATH. # device_tags = ["ID_FS_TYPE", "ID_FS_USAGE"] # ## Using the same metadata source as device_tags, you can also customize the ## name of the device via templates. ## The 'name_templates' parameter is a list of templates to try and apply to ## the device. The template may contain variables in the form of '$PROPERTY' or ## '${PROPERTY}'. The first template which does not contain any variables not ## present for the device is used as the device name tag. ## The typical use case is for LVM volumes, to get the VG/LV name instead of ## the near-meaningless DM-0 name. # name_templates = ["$ID_FS_LABEL","$DM_VG_NAME/$DM_LV_NAME"] [[inputs.docker]] ## Docker Endpoint ## To use TCP, set endpoint = "tcp://[ip]:[port]" ## To use environment variables (ie, docker-machine), set endpoint = "ENV" endpoint = "unix:///var/run/docker.sock" # ## Set to true to collect Swarm metrics(desired_replicas, running_replicas) gather_services = false # ## Only collect metrics for these containers, collect all if empty container_names = [] # ## Set the source tag for the metrics to the container ID hostname, eg first 12 chars source_tag = false # ## Containers to include and exclude. Globs accepted. ## Note that an empty array for both will include all containers container_name_include = [] container_name_exclude = [] # ## Container states to include and exclude. Globs accepted. ## When empty only containers in the "running" state will be captured. ## example: container_state_include = ["created", "restarting", "running", "removing", "paused", "exited", "dead"] ## example: container_state_exclude = ["created", "restarting", "running", "removing", "paused", "exited", "dead"] # container_state_include = [] # container_state_exclude = [] # ## Timeout for docker list, info, and stats commands timeout = "5s" # ## Whether to report for each container per-device blkio (8:0, 8:1...), ## network (eth0, eth1, ...) and cpu (cpu0, cpu1, ...) stats or not. ## Usage of this setting is discouraged since it will be deprecated in favor of 'perdevice_include'. ## Default value is 'true' for backwards compatibility, please set it to 'false' so that 'perdevice_include' setting ## is honored. perdevice = true # ## Specifies for which classes a per-device metric should be issued ## Possible values are 'cpu' (cpu0, cpu1, ...), 'blkio' (8:0, 8:1, ...) and 'network' (eth0, eth1, ...) ## Please note that this setting has no effect if 'perdevice' is set to 'true' # perdevice_include = ["cpu"] # ## Whether to report for each container total blkio and network stats or not. ## Usage of this setting is discouraged since it will be deprecated in favor of 'total_include'. ## Default value is 'false' for backwards compatibility, please set it to 'true' so that 'total_include' setting ## is honored. total = false # ## Specifies for which classes a total metric should be issued. Total is an aggregated of the 'perdevice' values. ## Possible values are 'cpu', 'blkio' and 'network' ## Total 'cpu' is reported directly by Docker daemon, and 'network' and 'blkio' totals are aggregated by this plugin. ## Please note that this setting has no effect if 'total' is set to 'false' # total_include = ["cpu", "blkio", "network"] # ## Which environment variables should we use as a tag ##tag_env = ["JAVA_HOME", "HEAP_SIZE"] # ## docker labels to include and exclude as tags. Globs accepted. ## Note that an empty array for both will include all labels as tags docker_label_include = [] docker_label_exclude = [] # ## Optional TLS Config # tls_ca = "/etc/telegraf/ca.pem" # tls_cert = "/etc/telegraf/cert.pem" # tls_key = "/etc/telegraf/key.pem" ## Use TLS but skip chain & host verification # insecure_skip_verify = false [[inputs.mem]] # no configuration [[inputs.net]] ## By default, telegraf gathers stats from any up interface (excluding loopback) ## Setting interfaces will tell it to gather these explicit interfaces, ## regardless of status. ## # interfaces = ["eth0"] ## ## On linux systems telegraf also collects protocol stats. ## Setting ignore_protocol_stats to true will skip reporting of protocol metrics. ## # ignore_protocol_stats = false ## [[inputs.processes]] # no configuration [[inputs.swap]] # no configuration [[inputs.system]] ## Uncomment to remove deprecated metrics. # fielddrop = ["uptime_format"] Exemple : ++
-
Salut @Sil51, Apres pas mal de galère et de bug depuis le passage à DSM 7 et Download Station 3.9, je te fais un petit retour qui ma débloqué. On vas pas passer par 4 chemins tu vas perdre toute ta configuration de DownloadStation mais tout fonctionnera normalement en le reconfigurant. Stop/désinstalle DownloadStation. Active le SSH (que tu désactivera à la fin) : Connect toi en SSH avec un logiciel (putty, terminal,...) Pour un compte admin sous terminal MacOS c'est : ssh Login_admin@adresse_serveur Tu mets ton mot de passe Vas dans le répertoire de configuration de DS Download (dans cette example c'est le volume3 mais pour toi ce sera peut-être volume1: cd /volume3/@appconf/DownloadStation Supprime les fichiers du répertoire (il te redemandera ton mot de passe) : sudo rm -r * Maintenant tu peux désactiver le SSH et réinstaller Download Station. Dis moi si c'est bon pour toi . ++