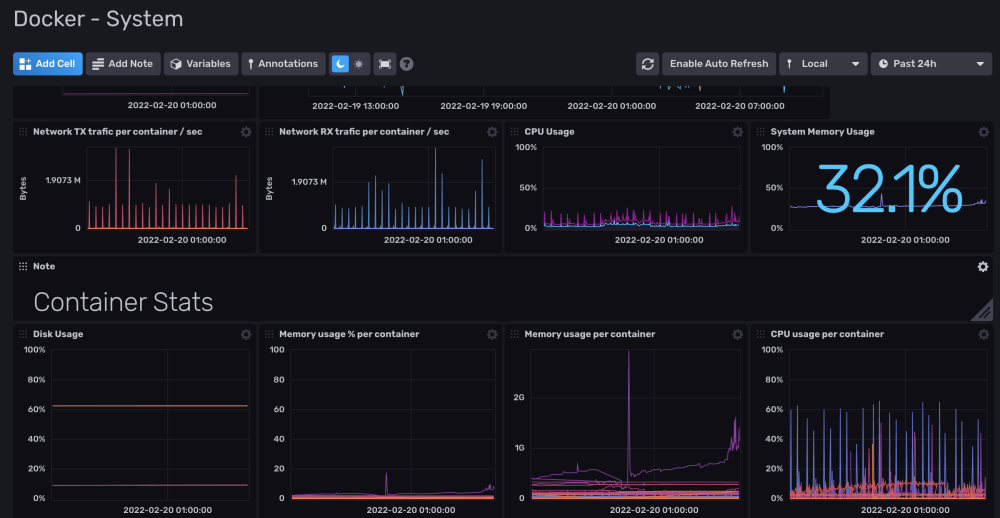
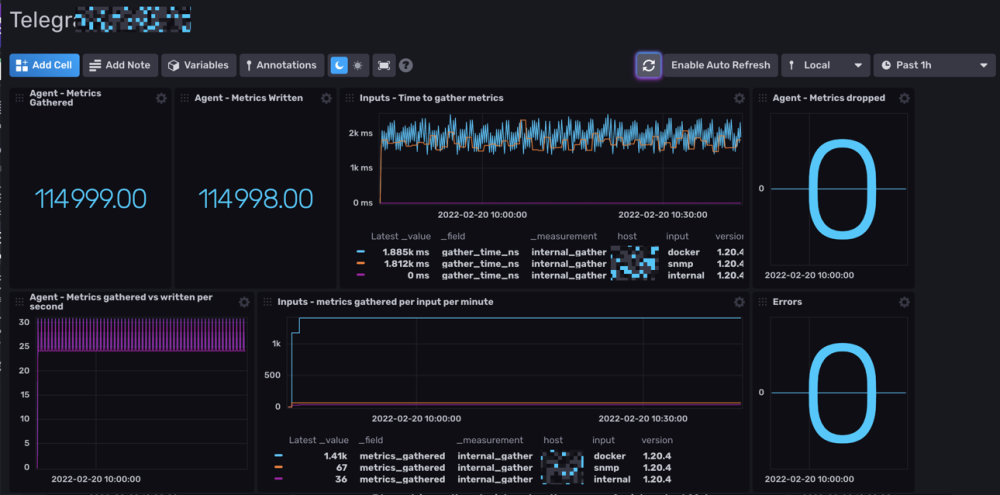
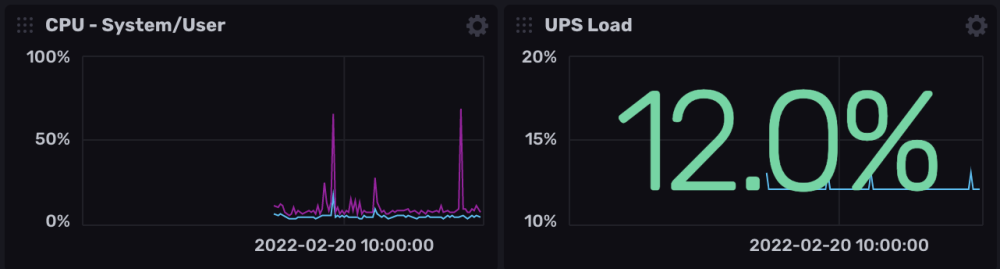
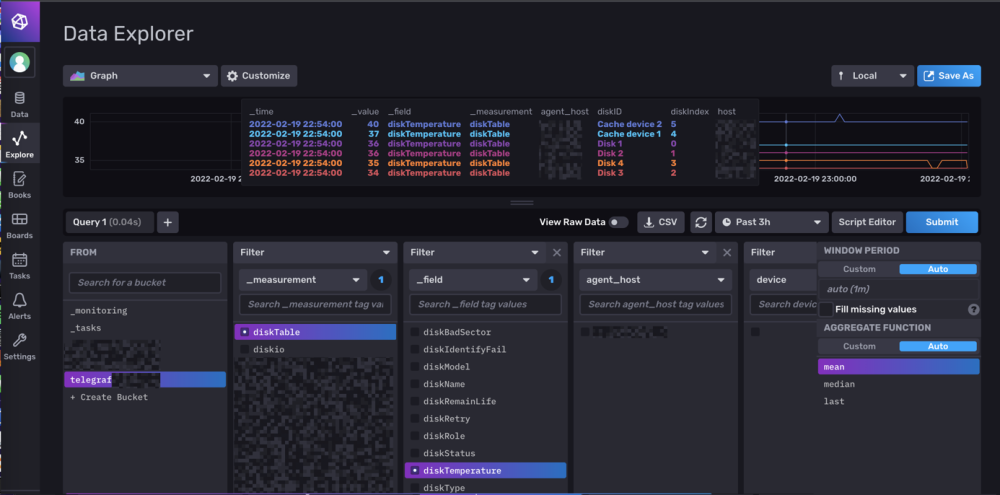
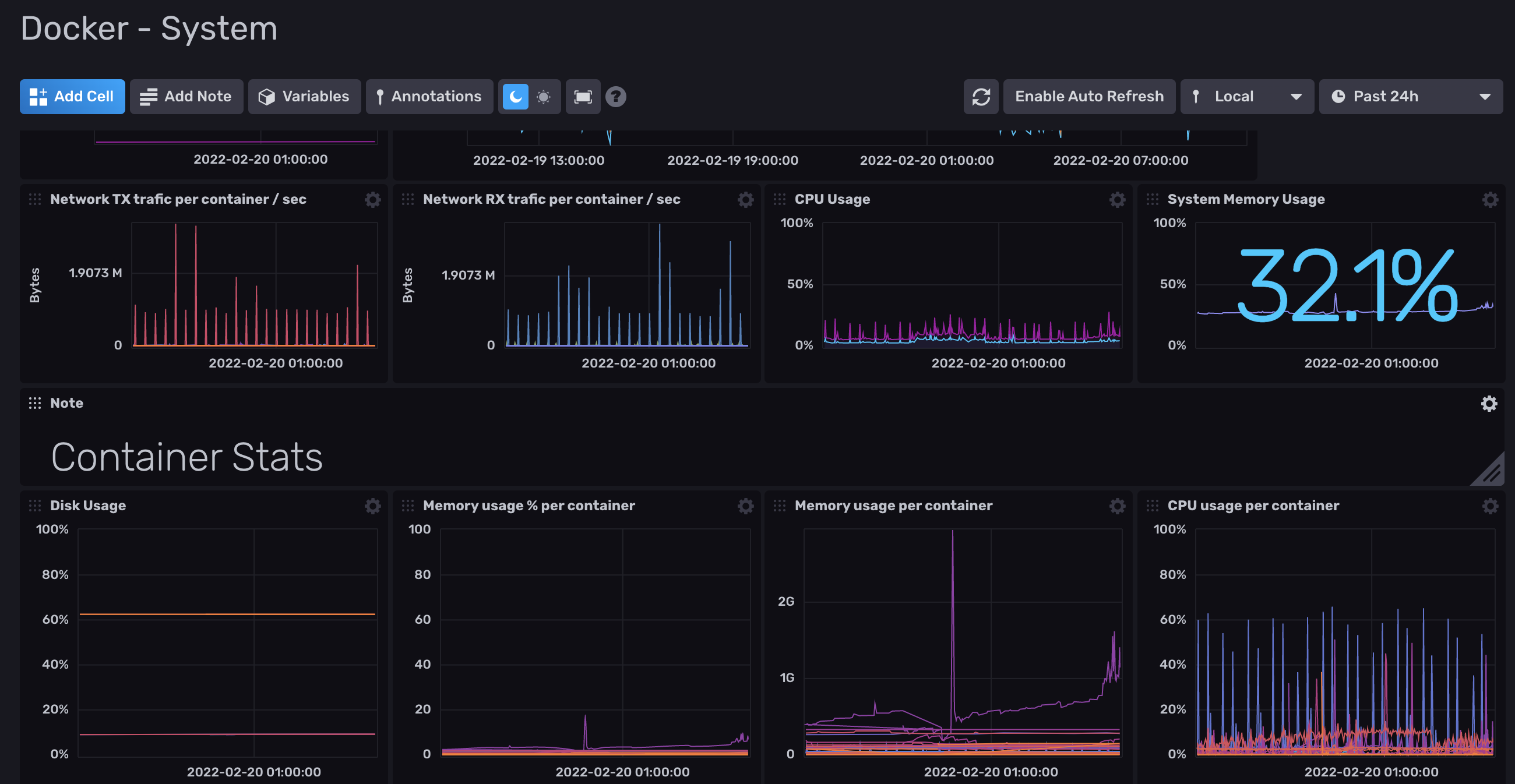
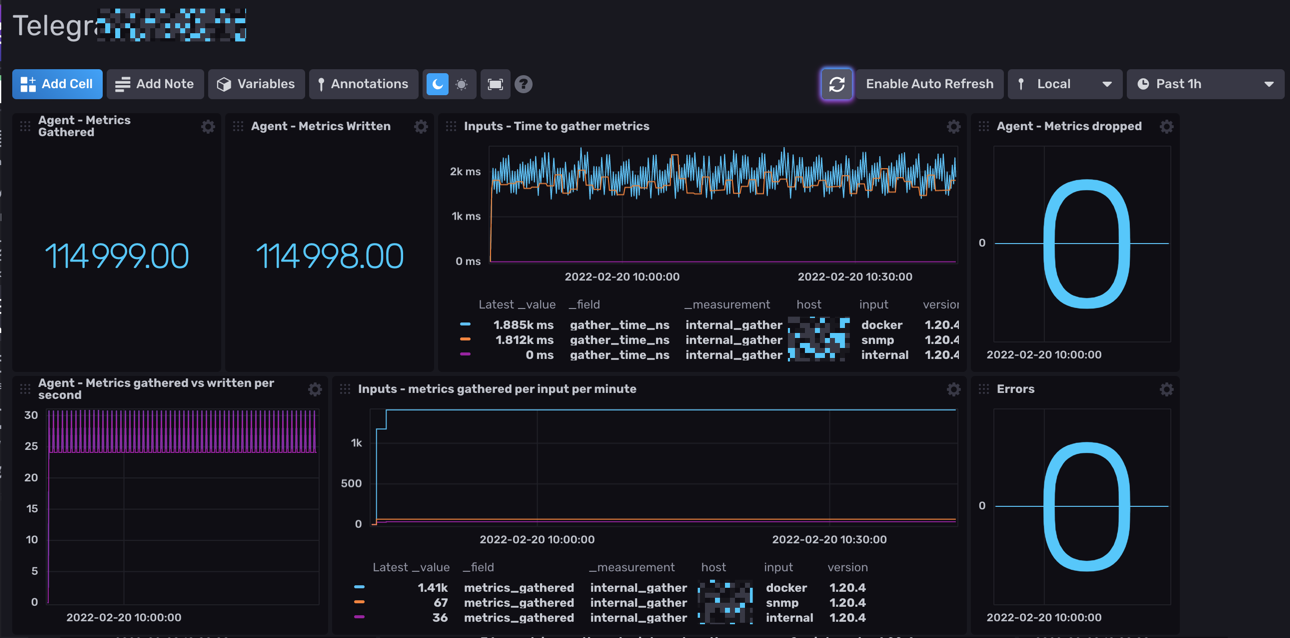
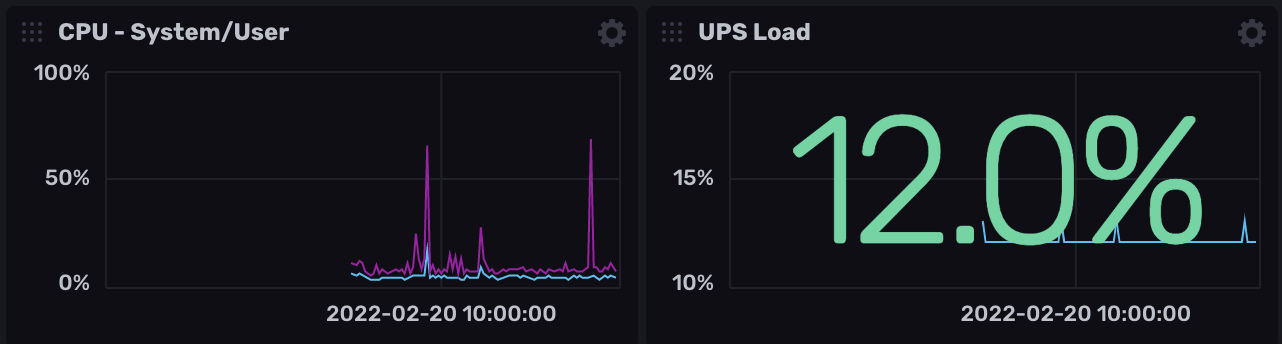
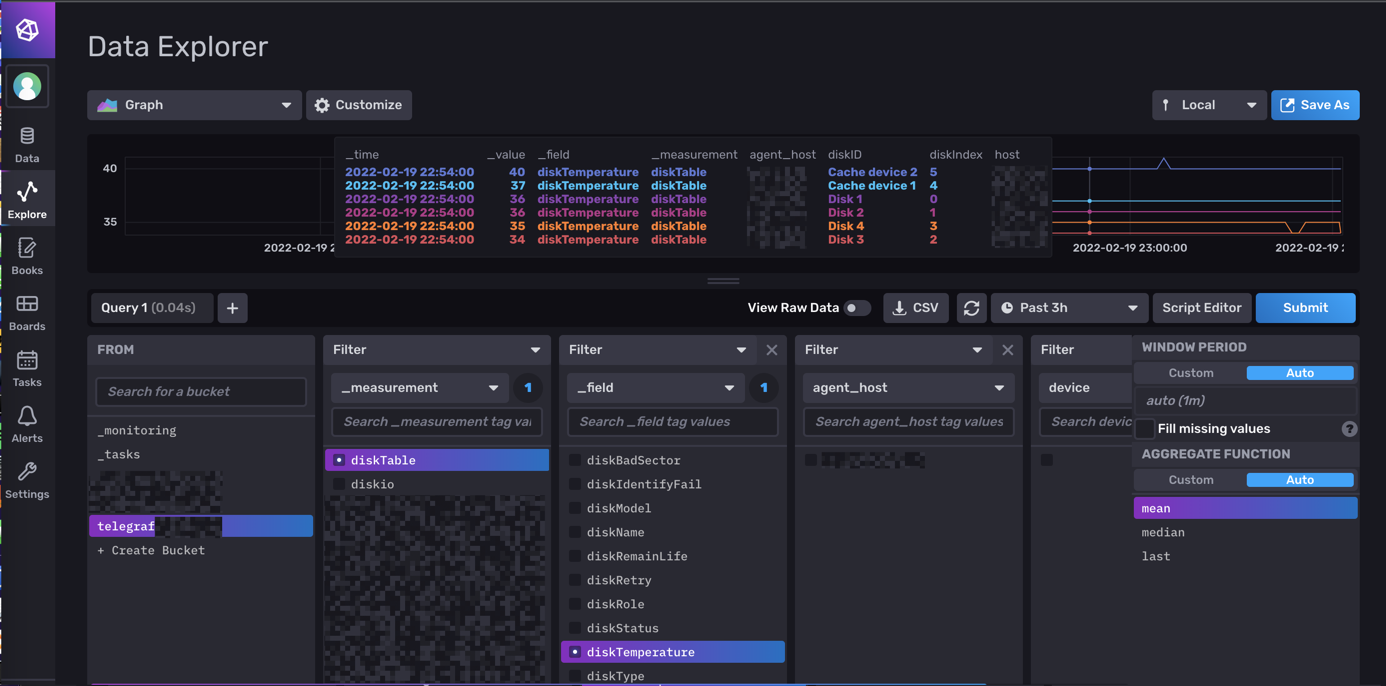
Hello tout le monde.
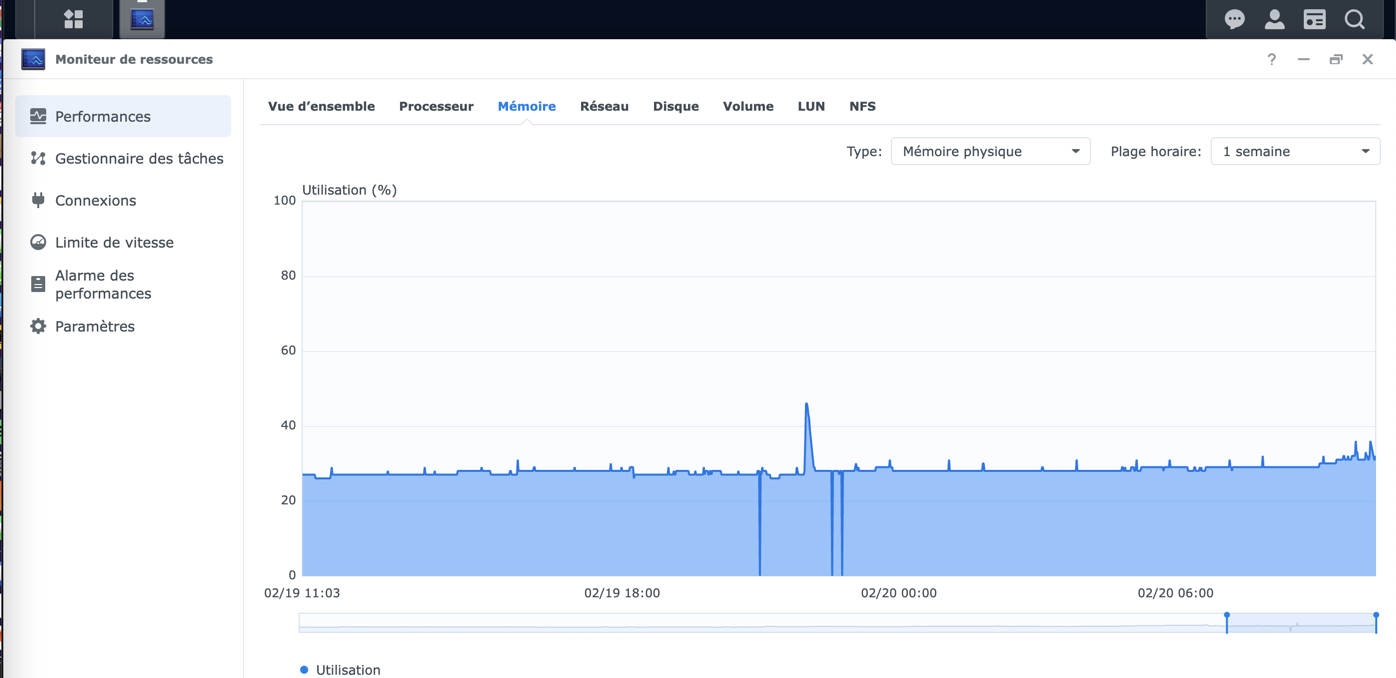
Etant sous dsm7 avec un DS918+, je cherchais a monitorer mon NAS et Docker.
@.Shad. Merci pour ton tuto. J'ai essayé... mais beaucoup d'erreur avec la particularité de ta configuration des UserGroups.
Je me suis mis au Docker il y à 2-3 mois donc je suis pas encore au top, mais du coup j'ai voulus me lancer dans l'aventure.
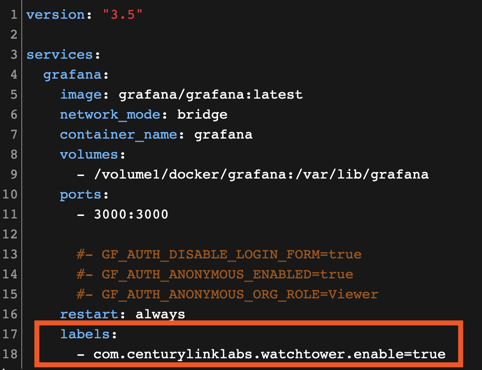
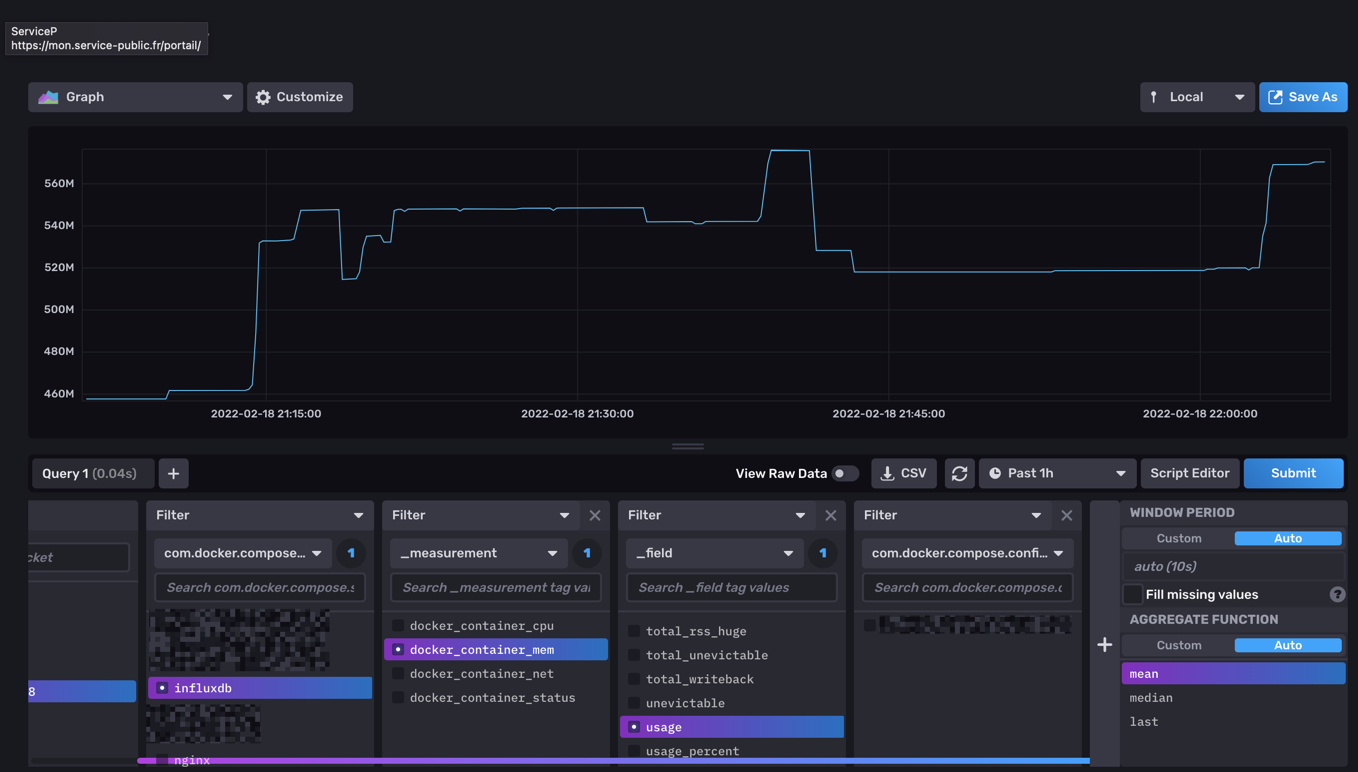
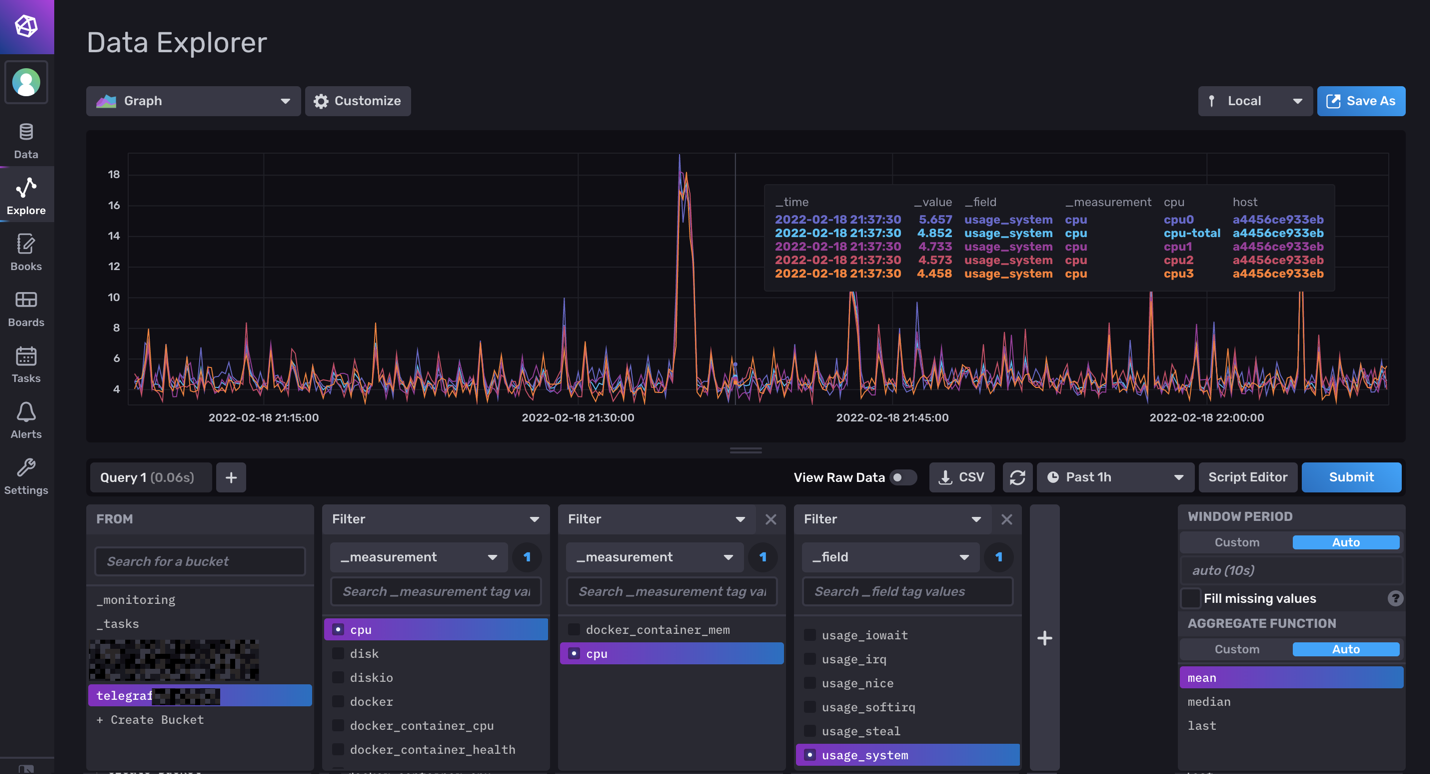
A l'instant T, j'ai dockerisé Influxdb 2.1.1 et telegraf:latest.
Ce que je n'ai pas fait :
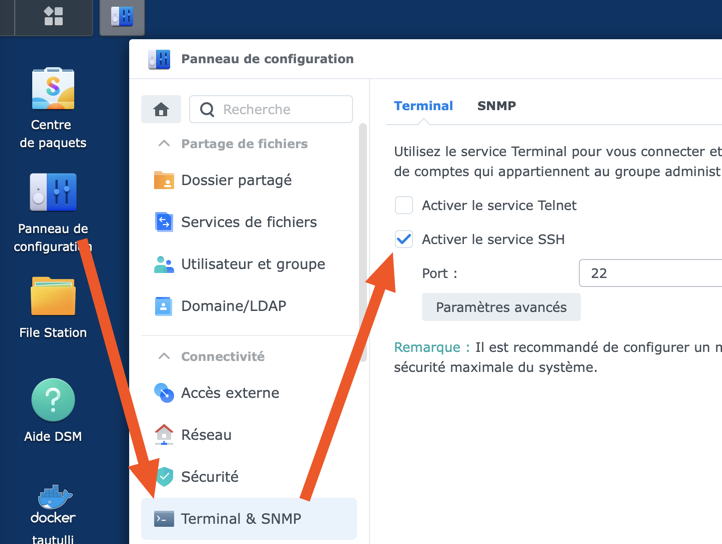
- Activation de SNMP
- Créer un User ou USERGROUP telegraf
- Changer les droits de docker.sock
Ce que j'ai fait :
- Changer les permissions des dossiers influxdb et telegraf utilisé par mes containers
- Fait mes propres dockercompose (et tu as été une source d'inspiration).
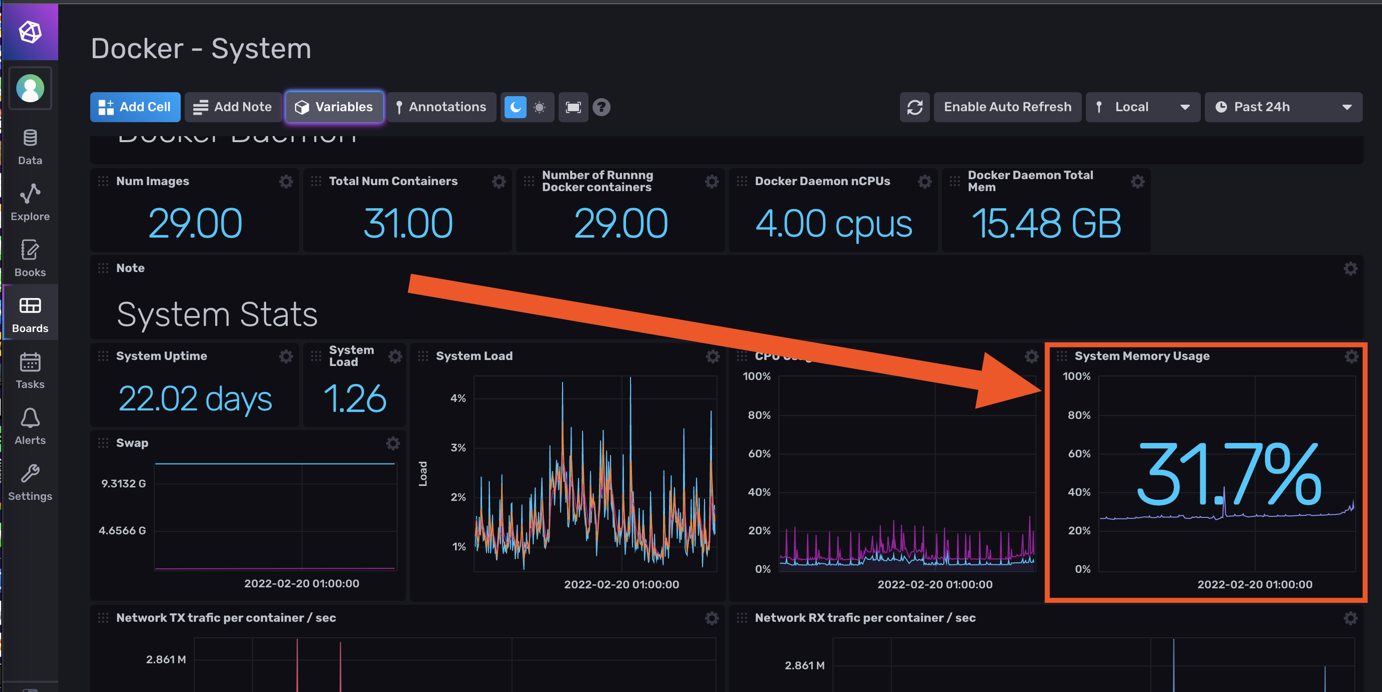
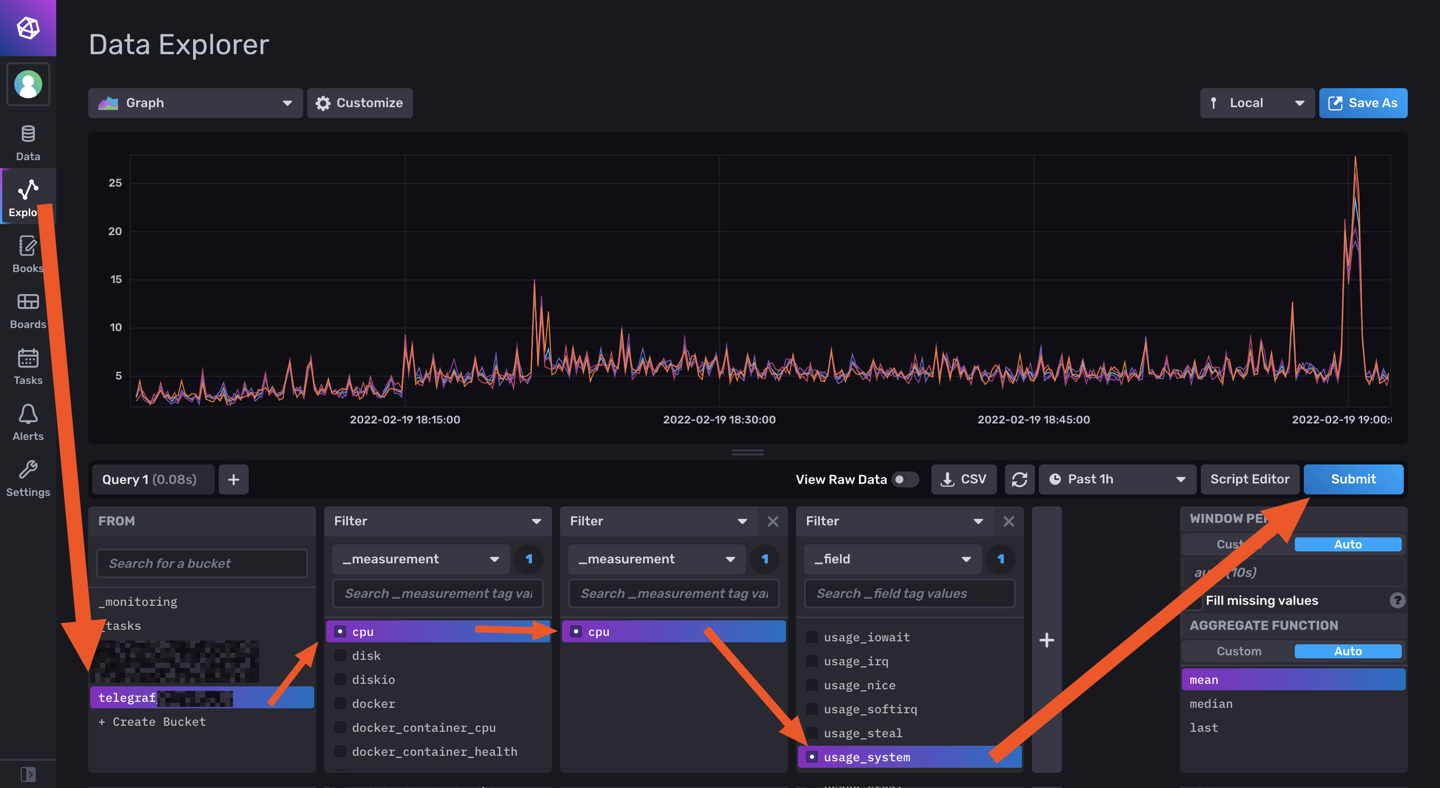
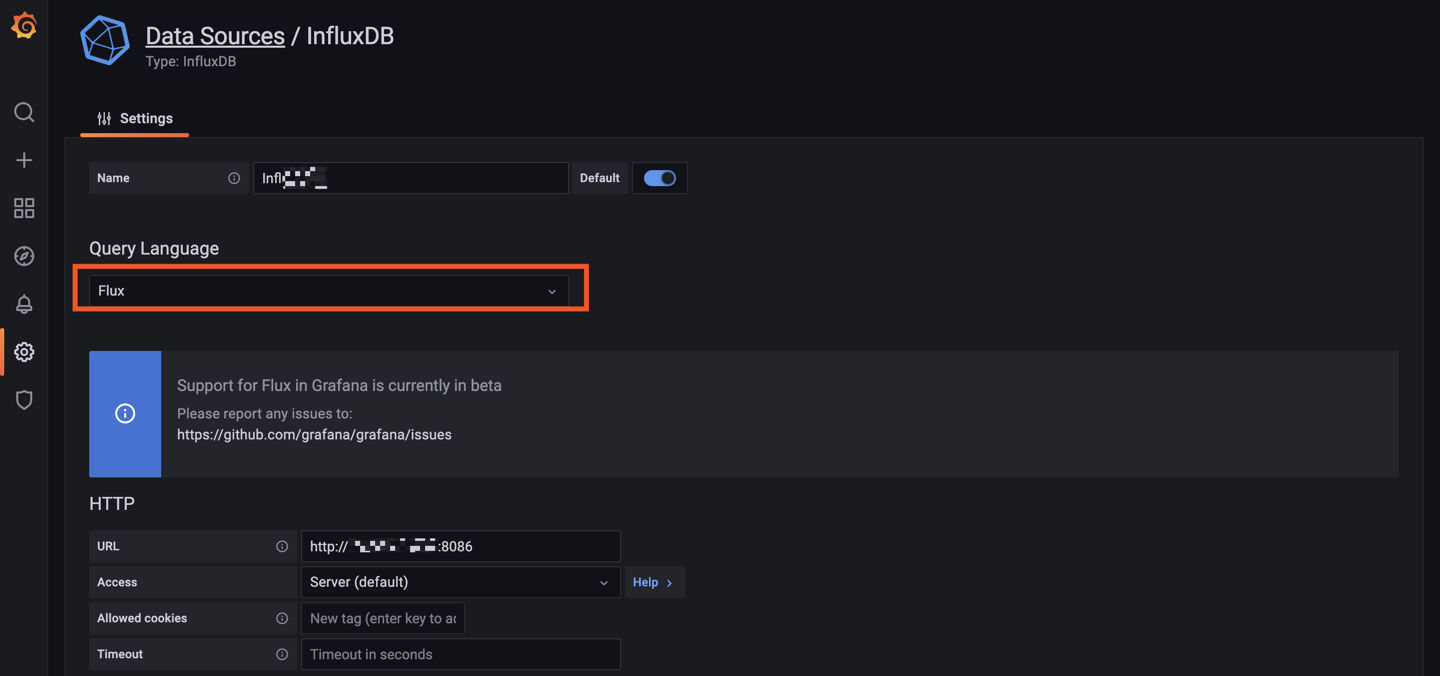
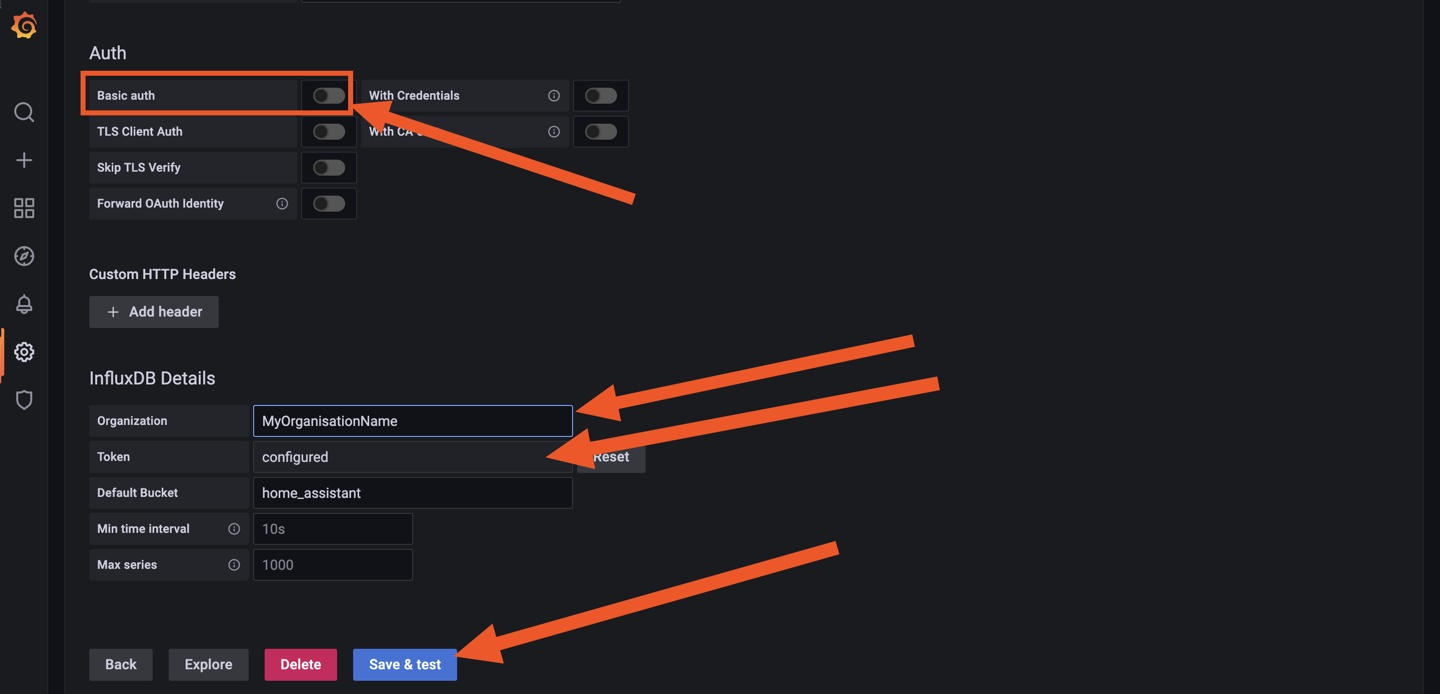
La je m'attaque à Grafana quand j'ai un peu de temps (maintenant que je collect toutes les data du server/docker).
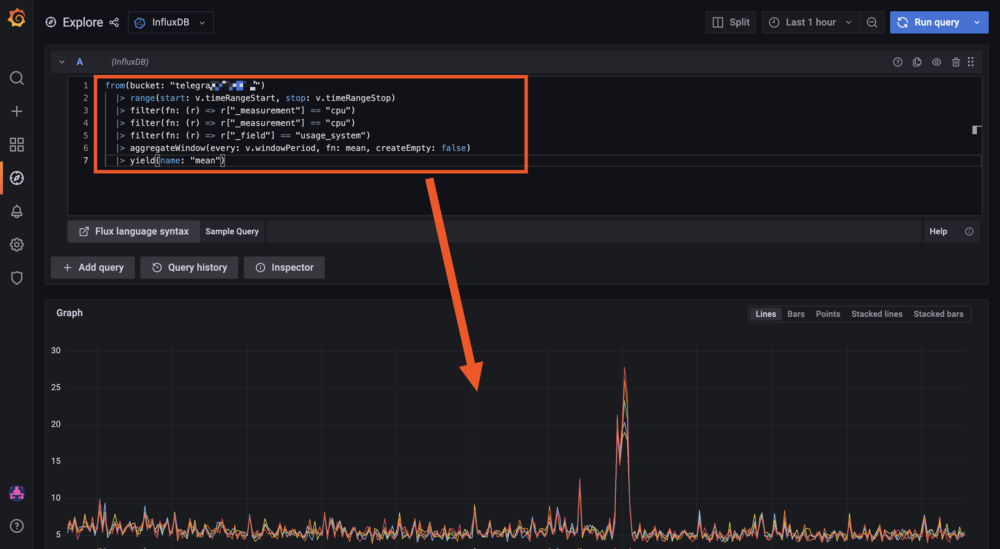
Juste pour info une partie de mon fichier telegraf.conf pour la remonté sans SNMP (attention pour influxdb 2.1.1 !!):
# Configuration for telegraf agent
[agent]
## Default data collection interval for all inputs
interval = "10s"
## Rounds collection interval to 'interval'
## ie, if interval="10s" then always collect on :00, :10, :20, etc.
round_interval = true
## Telegraf will send metrics to outputs in batches of at most
## metric_batch_size metrics.
## This controls the size of writes that Telegraf sends to output plugins.
metric_batch_size = 1000
## Maximum number of unwritten metrics per output. Increasing this value
## allows for longer periods of output downtime without dropping metrics at the
## cost of higher maximum memory usage.
metric_buffer_limit = 10000
## Collection jitter is used to jitter the collection by a random amount.
## Each plugin will sleep for a random time within jitter before collecting.
## This can be used to avoid many plugins querying things like sysfs at the
## same time, which can have a measurable effect on the system.
collection_jitter = "0s"
## Default flushing interval for all outputs. Maximum flush_interval will be
## flush_interval + flush_jitter
flush_interval = "10s"
## Jitter the flush interval by a random amount. This is primarily to avoid
## large write spikes for users running a large number of telegraf instances.
## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15s
flush_jitter = "0s"
## By default or when set to "0s", precision will be set to the same
## timestamp order as the collection interval, with the maximum being 1s.
## ie, when interval = "10s", precision will be "1s"
## when interval = "250ms", precision will be "1ms"
## Precision will NOT be used for service inputs. It is up to each individual
## service input to set the timestamp at the appropriate precision.
## Valid time units are "ns", "us" (or "µs"), "ms", "s".
precision = ""
## Log at debug level.
# debug = false
## Log only error level messages.
# quiet = false
## Log target controls the destination for logs and can be one of "file",
## "stderr" or, on Windows, "eventlog". When set to "file", the output file
## is determined by the "logfile" setting.
# logtarget = "file"
## Name of the file to be logged to when using the "file" logtarget. If set to
## the empty string then logs are written to stderr.
# logfile = ""
## The logfile will be rotated after the time interval specified. When set
## to 0 no time based rotation is performed. Logs are rotated only when
## written to, if there is no log activity rotation may be delayed.
# logfile_rotation_interval = "0d"
## The logfile will be rotated when it becomes larger than the specified
## size. When set to 0 no size based rotation is performed.
# logfile_rotation_max_size = "0MB"
## Maximum number of rotated archives to keep, any older logs are deleted.
## If set to -1, no archives are removed.
# logfile_rotation_max_archives = 5
## Pick a timezone to use when logging or type 'local' for local time.
## Example: America/Chicago
# log_with_timezone = ""
## Override default hostname, if empty use os.Hostname()
hostname = ""
## If set to true, do no set the "host" tag in the telegraf agent.
omit_hostname = false
[[outputs.influxdb_v2]]
## The URLs of the InfluxDB cluster nodes.
##
## Multiple URLs can be specified for a single cluster, only ONE of the
## urls will be written to each interval.
## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"]
urls = ["http://192.168.1.xxx:9999"]
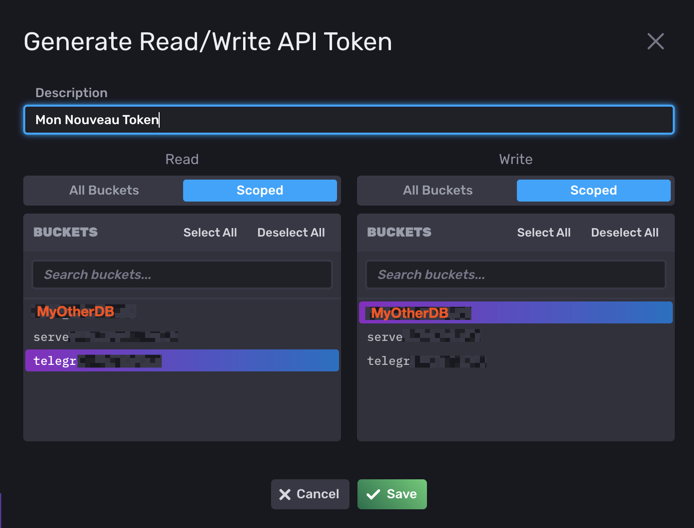
## Token for authentication.
token = "oiqhsx9xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=="
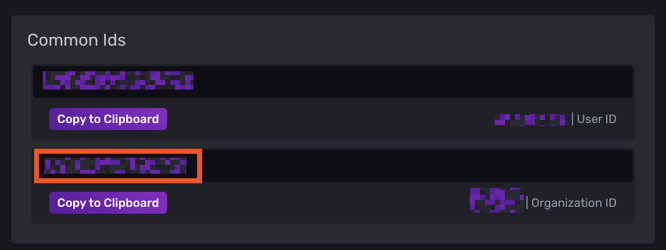
## Organization is the name of the organization you wish to write to; must exist.
organization = "d4xxxxxxxxxxxxxx"
## Destination bucket to write into.
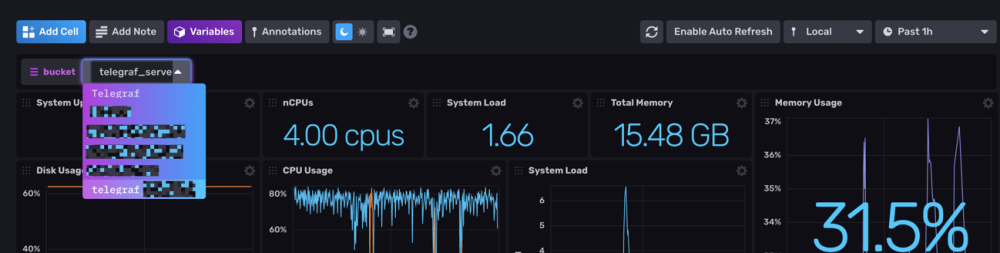
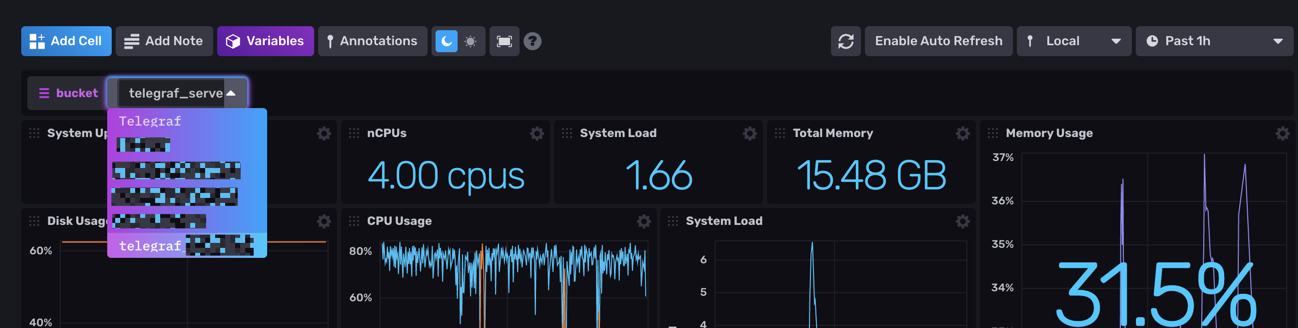
bucket = "telegraf_server"
## The value of this tag will be used to determine the bucket. If this
## tag is not set the 'bucket' option is used as the default.
# bucket_tag = ""
## If true, the bucket tag will not be added to the metric.
# exclude_bucket_tag = false
## Timeout for HTTP messages.
# timeout = "5s"
## Additional HTTP headers
# http_headers = {"X-Special-Header" = "Special-Value"}
## HTTP Proxy override, if unset values the standard proxy environment
## variables are consulted to determine which proxy, if any, should be used.
# http_proxy = "http://corporate.proxy:3128"
## HTTP User-Agent
# user_agent = "telegraf"
## Content-Encoding for write request body, can be set to "gzip" to
## compress body or "identity" to apply no encoding.
# content_encoding = "gzip"
## Enable or disable uint support for writing uints influxdb 2.0.
# influx_uint_support = false
## Optional TLS Config for use on HTTP connections.
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
#insecure_skip_verify = false
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## If true, collect raw CPU time metrics
collect_cpu_time = false
## If true, compute and report the sum of all non-idle CPU states
report_active = false
[[inputs.disk]]
## By default stats will be gathered for all mount points.
## Set mount_points will restrict the stats to only the specified mount points.
# mount_points = ["/"]
## Ignore mount points by filesystem type.
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
[[inputs.diskio]]
## By default, telegraf will gather stats for all devices including
## disk partitions.
## Setting devices will restrict the stats to the specified devices.
# devices = ["sda", "sdb", "vd*"]
## Uncomment the following line if you need disk serial numbers.
# skip_serial_number = false
#
## On systems which support it, device metadata can be added in the form of
## tags.
## Currently only Linux is supported via udev properties. You can view
## available properties for a device by running:
## 'udevadm info -q property -n /dev/sda'
## Note: Most, but not all, udev properties can be accessed this way. Properties
## that are currently inaccessible include DEVTYPE, DEVNAME, and DEVPATH.
# device_tags = ["ID_FS_TYPE", "ID_FS_USAGE"]
#
## Using the same metadata source as device_tags, you can also customize the
## name of the device via templates.
## The 'name_templates' parameter is a list of templates to try and apply to
## the device. The template may contain variables in the form of '$PROPERTY' or
## '${PROPERTY}'. The first template which does not contain any variables not
## present for the device is used as the device name tag.
## The typical use case is for LVM volumes, to get the VG/LV name instead of
## the near-meaningless DM-0 name.
# name_templates = ["$ID_FS_LABEL","$DM_VG_NAME/$DM_LV_NAME"]
[[inputs.docker]]
## Docker Endpoint
## To use TCP, set endpoint = "tcp://[ip]:[port]"
## To use environment variables (ie, docker-machine), set endpoint = "ENV"
endpoint = "unix:///var/run/docker.sock"
#
## Set to true to collect Swarm metrics(desired_replicas, running_replicas)
gather_services = false
#
## Only collect metrics for these containers, collect all if empty
container_names = []
#
## Set the source tag for the metrics to the container ID hostname, eg first 12 chars
source_tag = false
#
## Containers to include and exclude. Globs accepted.
## Note that an empty array for both will include all containers
container_name_include = []
container_name_exclude = []
#
## Container states to include and exclude. Globs accepted.
## When empty only containers in the "running" state will be captured.
## example: container_state_include = ["created", "restarting", "running", "removing", "paused", "exited", "dead"]
## example: container_state_exclude = ["created", "restarting", "running", "removing", "paused", "exited", "dead"]
# container_state_include = []
# container_state_exclude = []
#
## Timeout for docker list, info, and stats commands
timeout = "5s"
#
## Whether to report for each container per-device blkio (8:0, 8:1...),
## network (eth0, eth1, ...) and cpu (cpu0, cpu1, ...) stats or not.
## Usage of this setting is discouraged since it will be deprecated in favor of 'perdevice_include'.
## Default value is 'true' for backwards compatibility, please set it to 'false' so that 'perdevice_include' setting
## is honored.
perdevice = true
#
## Specifies for which classes a per-device metric should be issued
## Possible values are 'cpu' (cpu0, cpu1, ...), 'blkio' (8:0, 8:1, ...) and 'network' (eth0, eth1, ...)
## Please note that this setting has no effect if 'perdevice' is set to 'true'
# perdevice_include = ["cpu"]
#
## Whether to report for each container total blkio and network stats or not.
## Usage of this setting is discouraged since it will be deprecated in favor of 'total_include'.
## Default value is 'false' for backwards compatibility, please set it to 'true' so that 'total_include' setting
## is honored.
total = false
#
## Specifies for which classes a total metric should be issued. Total is an aggregated of the 'perdevice' values.
## Possible values are 'cpu', 'blkio' and 'network'
## Total 'cpu' is reported directly by Docker daemon, and 'network' and 'blkio' totals are aggregated by this plugin.
## Please note that this setting has no effect if 'total' is set to 'false'
# total_include = ["cpu", "blkio", "network"]
#
## Which environment variables should we use as a tag
##tag_env = ["JAVA_HOME", "HEAP_SIZE"]
#
## docker labels to include and exclude as tags. Globs accepted.
## Note that an empty array for both will include all labels as tags
docker_label_include = []
docker_label_exclude = []
#
## Optional TLS Config
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
# insecure_skip_verify = false
[[inputs.mem]]
# no configuration
[[inputs.net]]
## By default, telegraf gathers stats from any up interface (excluding loopback)
## Setting interfaces will tell it to gather these explicit interfaces,
## regardless of status.
##
# interfaces = ["eth0"]
##
## On linux systems telegraf also collects protocol stats.
## Setting ignore_protocol_stats to true will skip reporting of protocol metrics.
##
# ignore_protocol_stats = false
##
[[inputs.processes]]
# no configuration
[[inputs.swap]]
# no configuration
[[inputs.system]]
## Uncomment to remove deprecated metrics.
# fielddrop = ["uptime_format"]
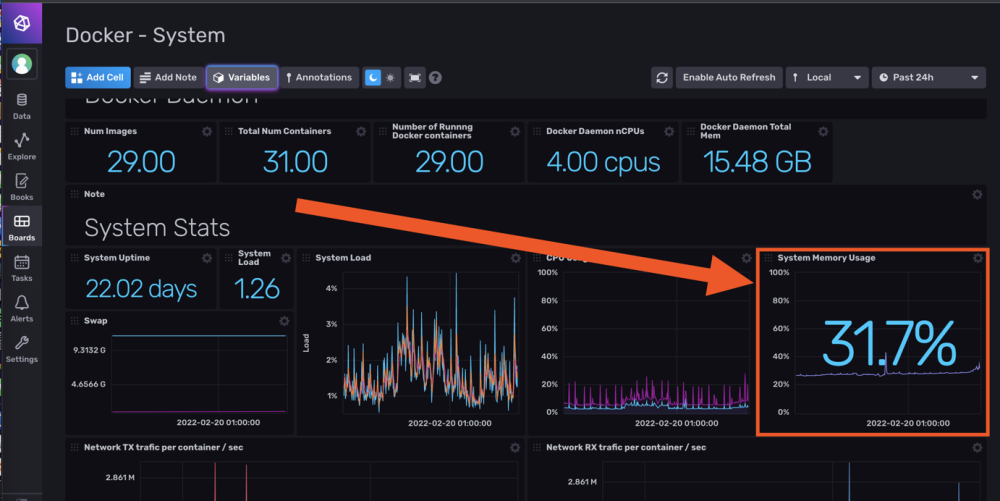
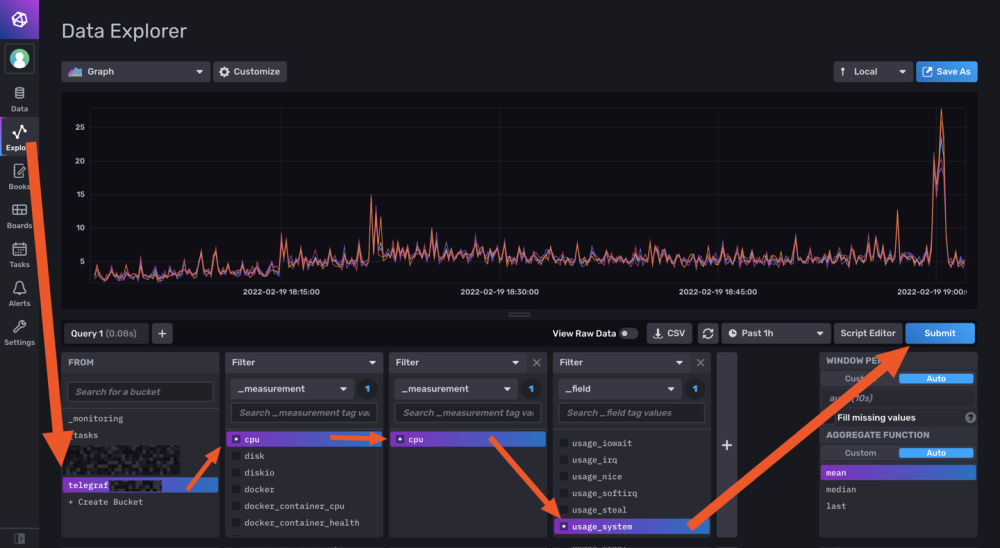
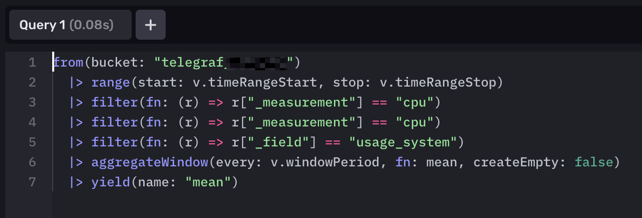
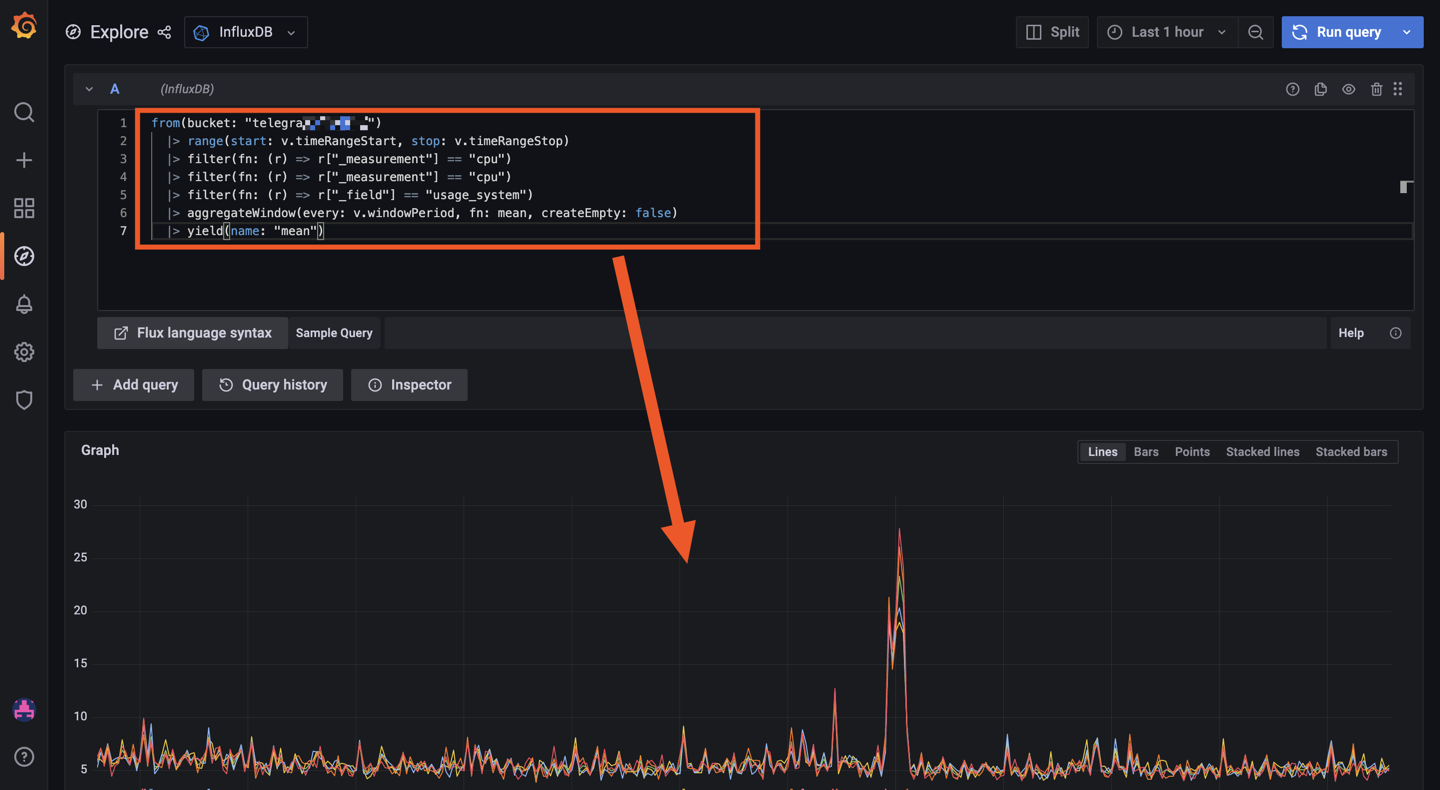
Exemple :
++