JeanSimon
-
Compteur de contenus
55 -
Inscription
-
Dernière visite
Tout ce qui a été posté par JeanSimon
-
Les Disques Durs Compatibles ?
JeanSimon a répondu à un(e) sujet de Thirganor dans Matériels Compatibles
Re! J'ai les réponses à mes questions. Question envoyé au support : Bonjour, Je projette d'acheter des HDD Seagate 10To (ST10000VN0004 - 1ZD101) répertoriés comme compatibles avec mon NAS sur votre site mais on m'a fait remarquer je devais faire attention à taille maximale de volume simple. En effet dans les documentations (qui date de la mise en vente du NAS) il est mentionné que la taille maximale de volume simple sur ce modèle est limitée à 16To. Pouvez vous me confirmer que si je prends 4 disques de 10To je pourrais faire un volume de 30To en RAID5? Si ce n'est pas le cas, quel est la taille maximale de volume simple que je peux atteindre avec ce NAS? Et plus généralement, ou est-ce que je peux trouver cette information (à jour) pour tous vos modèles? Merci d'avance pour votre aide. Réponse du support: Bonjour, Tout d'abord, nous vous remercions de l’intérêt que vous portez à nos produits. La taille maximale de 16To était indiqué due au fait que les disque de capacité maximale supportés étaient des disques de 4To. A présent, cette limite n'est plus effective, et vous pouvez vous baser sur notre liste de compatibilité pour la taille maximale de disques supportés par ce modèle. Vous devriez donc pouvoir créer un volume dépassant 16To. Cordialement, Idriss - Synology Technical Support Relance de ma part: Bonjour, Merci pour votre réponse. Par contre de quel liste de compatibilité est-ce que vous parlez? Celle des disques dur? Est-ce que je peux partir du principe ou à partir du moment ou un disque dur apparait comme compatible avec mon NAS sur votre site https://www.synology.com/fr-fr/compatibility?search_by=category&category=hdds&p=1¬_recommend_mode=false Je pourrais faire un volume avec la taille maximale possible? Comme par exemple volume de 40To avec 4 disques de 10To? Désolé d'insister mais comme ce sont des achats lourds financièrement, je tiens à être 100% sur de moi. Merci d'avance. Dernière réponse du support: Bonjour, Oui, la limite sur nos modèles 64bit par volume est de 108TB. Dans votre cas, tant que le volume à été créer sur un NAS en 64bits (et non importé depuis un autre NAS), vous ne serez pas limités par la taille de 16TB. Cordialement, Idriss - Synology Technical Support Je pense que la question est définitivement claire pour l'instant en attendant l'arrivée des SSD 100To à 200€ non? -
Les Disques Durs Compatibles ?
JeanSimon a répondu à un(e) sujet de Thirganor dans Matériels Compatibles
Okk! Bon ben j'suis en train de jeter quand même un oeul dans la base de connaissance pour voir s'il n'y a pas quelque chose de clair pour mon modèle. Si je trouve rien je demanderais au support. Au passage je leur demanderais s'ils ont un pas un récap de tous les modèles histoire de le filer à la postérité . -
Les Disques Durs Compatibles ?
JeanSimon a répondu à un(e) sujet de Thirganor dans Matériels Compatibles
Effectivement vu comme ça, ça change tout. Je pensais que ce genre de paramètre logiciel ne dépendait que de la version de DSM installée. Du coup je suppose qu'il n'y a que le support qui puisse à cette question? Étant donné que la doc officielle date de la date de sortie du NAS... -
Les Disques Durs Compatibles ?
JeanSimon a répondu à un(e) sujet de Thirganor dans Matériels Compatibles
Re! Finalement j'ai trouvé. En utilisant le lien posté dans la dernière réponse de Mic13710 qui check la compatibilité par HDD et non pas par référence de syno (comme je le faisais) j'ai eu ma réponse claire. Et du coup il même compatible avec les Seagate 10To! Le renouvellement du NAS n'est donc plus à l'ordre du jour. Par contre les disques 10To me font du pied maintenant... -
Les Disques Durs Compatibles ?
JeanSimon a répondu à un(e) sujet de Thirganor dans Matériels Compatibles
Salut à tous, J'ai un DS412+ dont je suis très très content (malgré un faut bond de 2 HDD l'année dernière) et je pensais à renouveler mes disque car je commence à être juste en espace. Actuellement j'ai 4 disques de 3To (WDC & Seagate) qui fonctionne sans problème. Je comptais prendre du matériel beaucoup plus gros, genre 8To par disque mais je n'arrive pas à savoir définitivement s'ils fonctionnerons avec mon NAS. Sur le site de compatibilité syno il y a écrit sur certains "Ce disque est uniquement compatible avec les modèles Synology NAS qui sont expédiés depuis Juin 2014." Le miens apparemment date de 2012. Mais d'un autre coté sur le site il y a un bouton "Modèles incompatibles", et lorsque je clic dessus (en 8To) il n'y a qu'un seul modèle Seagate qui apparait. Est-ce que du coup ça sous entends que tous les autres sont supposés compatibles mais qu'ils ne voudraient pas se "mouiller" en cas de pépin? Si vous connaissez des modèles 6, 8 ou même 10To compatibles (soyons fous!), je suis preneur au passage. Merci à tous -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Retour un peu tardif. Dans un premier temps, le technicien m'a communiqué leur procédure qui est la suivante : How to rescue deleted iSCSI LUN File-level LUN without Advanced LUN feature The File-level LUN without Advanced LUN feature are created as file / sparse file, when user deletes the LUN, it means to delete the file(s) from volume. Thus to rescue such LUN, you will need to run some undelete utilities, eg. extundelete, photorec …etc to find back the files. extundelete => http://extundelete.sourceforge.net/options.html photorec => http://www.cgsecurity.org/wiki/PhotoRec File-level LUN with Advanced LUN feature If the LUN is with Advanced LUN feature enabled, it is created as maps and pool of blocks. The LUN is a set of blocks which are registered in map file. When the LUN is deleted, those blocks will be reclaimed/un-registered and could not be recovered. But if the scenario is that user removes the "whole volume" and thus the LUN is removed, there is still hope. Please follow the steps to rescue the LUN: 1. Recover the volume/configuration in offline/syno_poweroff_task mode 2. Move the deleted LUN map from @EP_trash to @iSCSItrg folder in the same volume (to avoid the reclamation, very important). 3. Rename the map files, then reboot the system. Block-level LUN If it is block-level LUN, removing the LUN is just like to remove the RAID volume or LVM volume, you could simply recover them as recovering deleted volume. One more step you might need to do is to adjust the synoblock configuration if the LUN is not correctly remounted to system. If it is block-level LUN based on RAID, please ensure the synoblock is set as “iscsi_LUN-1” (1 could be replaced by any number). You could modify the space path by "synospace --synoblock -s /dev/sdX -v iscsi_LUN-1" (for example) IF it is block-level LUN based on LVM, please ensure the synoblock is correctly configured, synospace --lv_meta –a -p VG_PATH –k LUN_BLOCK_DEVICE_NAME -v LUN_NAME VG_PATH: such as /dev/vg1 LUN_BLOCK_DEVICE_NAME: use lvs to check the lv name, such as iscsi_0 LUN_NAME: usually restore it to default name, such as LUN-1 ------------------------------------------------------- Après quoi je lui indiqué que je ne rentrais dans aucun des cas vu que la taille de mes fichiers étaient incohérente etc... Il a alors pris la main sur mon NAS avec ses collègue en thailande ou à Taywan (j'ai un doute) et ils ont fait tout plein de choses et redémarré. Après reboot j'avais un disque de plus qui était UP donc mon ISCSI UP aussi. Voici les commandes qu'il a exécuté dans mon cas précis à moi : a) vérifier l'historique de votre volume dans /etc/space/ b) vérifier l'état du raid avec cette commande cat /proc/mdstat c) Vérifier les disques avec cette commande sfdisk -l d) démonter le Raid avec cette commande mdadm -Sf /dev/md2 e) essayer de monter le volume au moins avec 3 disques "utilisant plusieurs combinaisons (c'était obligatoire, vu votre gros volume LUN)" avec cette commande (RAID classique si ma mémoire est bonne....si pour un volume SHR utiliser sd[abc]3 ou SD[abd]3) mdadm -AfR /dev/md2 /dev/sd[abc]5 et mdadm -AfR /dev/md2 /dev/sd[abd]5 f) essayer la réparation du système de fichier ext4 avec cette commande nohup fsck.ext4 -yvf /dev/mdX g) si le système des fichiers est réparé...redémarrer le NAS avec la commande reboot h) vérifier si le volume est bien monté avec au moins 3 disques...c'était vitale car votre volume le manque 3To, car vous avez un volume avec une protection de données sur un seul disque!! Voila vous savez tout maintenant! Au passage si quelqu'un à un lien pour réparer des secteurs delayed ou mort sur un HDD je suis preneur vu que j'ai 2 disque de 3To dans ce cas... :( -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Salut tout le monde. Je voulais juste vous dire que j'ai eu une réponse du support de synology qui a pris la main sur mon NAS à distance et a réussi à me faire remonter mon RAID avec 3 disques. Du coup il était seulement en dégradé et j'ai pu remonter mon LUN en lecture seule et faire mes copies. Bon il a replanté pendant la copie mais j'avais sorti les fichiers essentiels donc c'est plus vraiment un problème. J'ai demandé au mec du support comment il avait fait, il m'a filé tout le cheminement qu'il a emprunter. Je sais pas si ça intéresse quelqu'un mais du coup je pourrais éventuellement en faire un tuto... SI besoin faites moi signe. -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
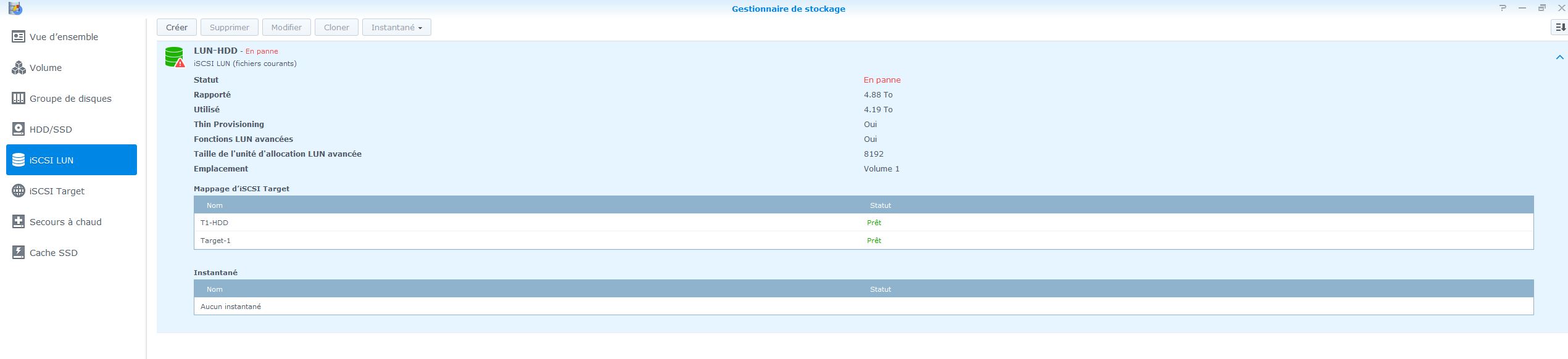
Bon! Je sais pas s'il y a toujours quelqu'un mais je suis toujours le nez en plein dans mon problème. J'ai avancé un chouilla mais pas plus. J'ai pu récupéré ce qu'il y avait dans mes dossiers partagés, mais le plus important, mon disque iSCSI reste innaccessible. J'ai ouvert un ticket chez syno, on m'avait dis sur le chat qu'il répondaient en général en 24h mais la ça fait presque 10 jours et toujours rien... Bref j'ai avancé sur le fait que j'ai récupéré mon ancien NAS DS211j, que j'ai remis à jour. J'ai acheté 2 disque 3To de remplacement que j'ai mis dedans, fais un JBOD pour avoir un espace de 5To, fait la vérif secteur par secteur des nouveaux disque pour m'assurer que tout est ok et j'ai tenté une sauvegarde du volume iSCSI craché du DS412+ vers le 211J mais ça a planté avec le joyeux message suivant "Network LUN Backup failed to backup task [My LUN Backup Set 1] to [192.168.100.114]. ([220] Unknown error:'220')". J'ai réessayé plusieurs fois mais rien à faire. Et en dernier recours j'ai essayé de copier à la main le volume iSCSI mais je me suis rendu compte d'un truc super bizarre. Le volume iSCSI que j'avais repéré dans le dossier /volume1/@iSCSITrg/ ne fait pas 5To comme il devrait mais 5Go! Et dans le dossier /volume1/@EP/ par contre il me dis des choses contradictoires. Lorsque je fais un du -sh /volume1/@EP/ du dossier il me dit qu'il fait 4,2To (ce qui correspondrait à la taille de mon volume). Mais lorsque je vais dans le dossier il que j'affiche la taille de chacun des fichiers j'en ai pour plus de 20To! Ce qui n'est pas possible vu que mon RAID ne faisait que 8,11To. Du coup ma question est : Est-ce que vous savez à quoi correspondent ces fichiers? Et lequel est réellement mon iSCSI? Car si j'arrive à le reprendre à la barbare comme ça et le remonter sur mon autre NAS, ça me vas tout autant! Je vous met la capture des fichiers du dossier EP et iSCSI.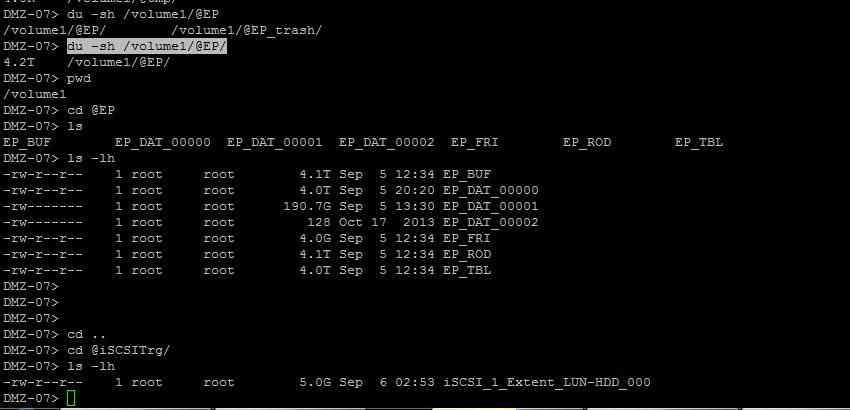
-
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
C'est ce que je me suis dis pour le 2 disques sur 4. Mais après je me suis aussi dis que si c'était ça, ben en réalité je n'aurais pas accès au dossier partagés non plus. Pourquoi ceux la je peux y accéder et pas l'iSCSI? Et la copie de l'intégralité du fichier j'y ai pensé mais il se pose une contrainte de "taille". Il fait 5To d'une part, et d'autre part comme c'est un bloc, je crois qu'il faut que tout se passe nickel pendant la copie sinon l'ensemble sera inutilisable. Mais peut-être que je me trompe? Mais par contre je ne sais pas comment le volume a été monté vu qu'il a été monté par le syno automatiquement au redémarrage. Comment est-ce que je peux vérifier la manière dont il est monté? Est-ce qu'il y a des chances que ça change quelque chose s'il était monté en lecture écriture, que je le démonte et le remonte en RO? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
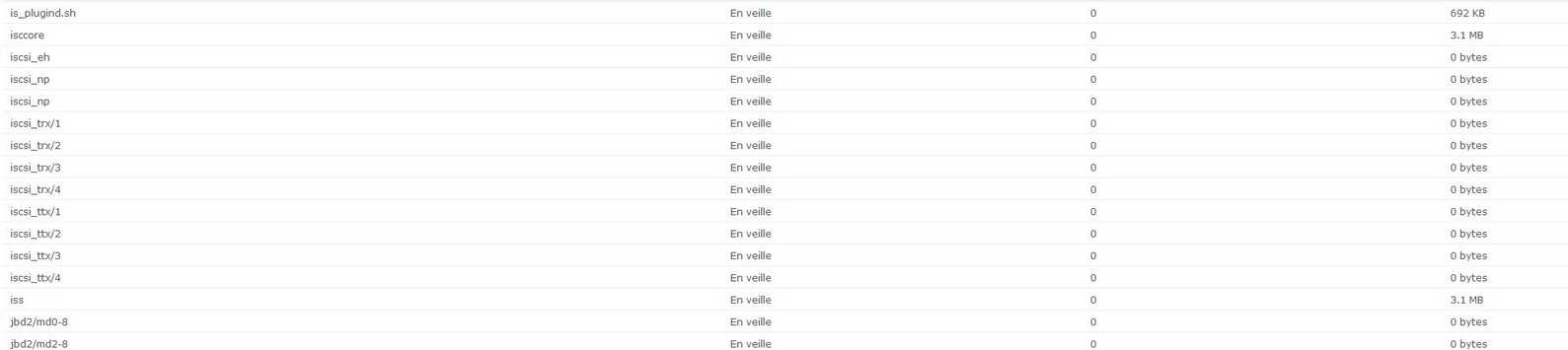
Bon! Je reviens! J'ai pris le temps de copier ce que je pouvais qui était en partage avant de tenter la dernière manip sur l'iSCSI et je voulais aussi avoir le weekend devant moi au cas ou ça se prolonge. J'ai redémarré mon NAS, il s'est remis à bipper j'ai arrêté l'alarme, jusqu'ici rien de spécial. Après ça je me suis connecté à l'interface et j'ai essayé de faire une nouvelle target en RO par là-bas. J'ai réussi à la faire, et j'ai même réussi à m'y connecter! Mais lorsque je m'y connecte il ne se passe rien, il ne me monte aucun disque. Du coup j'ai réessayé de remonter ma target habituelle pour voir si c'était pas la nouvelle qui était mal configuré mais impossible de la monter il me mettait un erreur comme quoi il y avait un périphérique pas prêt je crois. Enfait j'ai du désactiver l'authenticition qui était activé sur ma target pour pouvoir l'utiliser. Mais il se passait la même chose, ça ne me connecte à rien du tout. La target est monté mais je n'ai aucun disque de détecté dans windows. Je suis parti voir de plus près dans le NAS et j'ai bien vu effectivement que le RAID est en erreur, mais je viens de faire attention qu'il me dis aussi que mon volume iSCSI est en panne (voir PJ). Du coup je suis reparti tenter ma chance mais cette fois ci en ssh. Mais rien à faire du tout! Pour toutes les commandes ietadm que j'essaye de faire j'ai le joyeux message "Connection refused.". Je me suis dis que le service n'est peut-être pas lancé et j'ai essayé de trouver dans l'interface un endroit ou faire ça mais pas moyen. Par contre j'ai trouvé dans la liste des processus qu'il y en avait plein qui commencent par iscsi. Mais surtout qu'ils étaient tous en veille! (voir PJ) Est-ce que ce ne serai spas la source de mes connexions refusées? Si oui comment est-ce que je peux les lancer?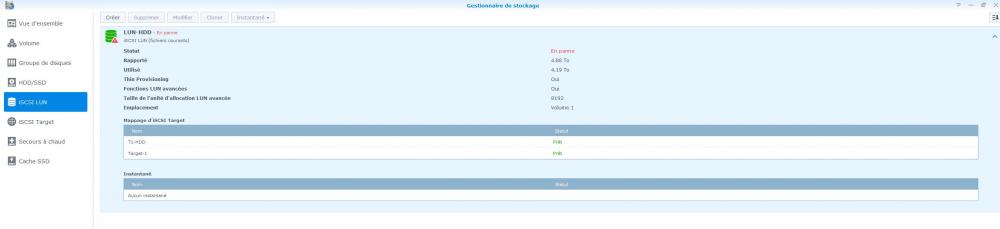
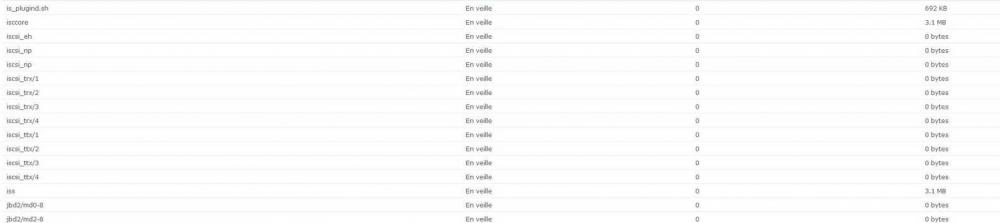
-
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Mais comment je monte un iSCSI en debug vu que le Syno n'est joignable qu'en SSH? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Ouais en gros vu comme ça, je prends n'importe quel marque et ça revient au même au final, ce sera au petit bonheur la chance... Une question tiens. Je suis en train d'essayer de comprendre la procédure que tu m'a linké pour l'adapter à mon cas. Par contre je me posais la question. Ce tuto va m'aider à monter mon iSCSI "manuellement" si j'ai bien compris, mais je vais donc bien devoir remettre mon NAS dans un état normal? Ou je peux faire ça en mode debug? Si je dois le remettre en mode normal, comment je fais pour le sortir du mode debug? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Je manquerais pas de faire un retour ça c'est sur! Même un tuto s'il faut! Pour le coup moi c'est le cas inverse. Ce sont mes WD qui m'ont laché et mes seagate qui sont toujours la sans broncher. Est-ce que les gammes peuvent avoir quelque chose à voir dans tout ça? (j'avais pris des WD green) -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
D'accord mais comment je fais pour monter mon iSCSI? Vu que c'est dessus que son stockés toutes les données vraiment importantes. Sachant que pour l'instant je ne le vois que sous la forme d'un gros fichier de 5To à travers ssh... Par contre je ne remonterais surement pas mon RAID avec ces 2 WD dedans ça c'est sur!!! Ils sont beaucoup trop volatiles, je peux pas leur faire confiance. Et puis ils ont peut-être bien un problème après tout. Vous avez des marques ou des types de disque préféré pour les NAS ofait? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Pourquoi c'est comique étant donné que c'est le sdC? J'ai l'impression que c'est le disque 3 physiquement mais qu'il l'a pris dans le RAID comme étant le disque 2 j'me trompe? Mais le fsck.ext4 -n -v /dev/md2 je viens de le refaire mais il est très rapide, genre même pas 30 secondes. Il manque rien à la commande? Je remet les résultats : DMZ-07> fsck.ext4 /dev/md2 e2fsck 1.42.6 (21-Sep-2012) 1.42.6-3776: is cleanly umounted, 422485/274272256 files, 1883956891/2194158192 blocks DMZ-07> fsck.ext4 -n -v /dev/md2 e2fsck 1.42.6 (21-Sep-2012) 1.42.6-3776: is cleanly umounted, 422485/274272256 files, 1883956891/2194158192 blocks DMZ-07> cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md2 : active raid5 sda3[0] sdc3[2](E) sdb3[4] 8776632768 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUE_] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [4/4] [UUUU] md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3] 2490176 blocks [4/4] [UUUU] unused devices: <none> DMZ-07> -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
C'est noté! J'ai quand même copié 2-3 trucs important qui trainaient et j'ai lancé le tout. Pour le fsck, la commande n'existe pas en tant que tel sur les syno, j'ai donc trouvé son équivalent en demandant à Gogole. Par contre le test est toujours en cours depuis 5min, je pense que ça doit être normal non? Par contre, il va ptet falloir que je sorte le syno de ce mode debug si je veux l'utiliser pour de vrai je pense. C'est quoi la commande? Sinon voila le résultat : DMZ-07> DMZ-07> umount /volume1 DMZ-07> mdadm --stop /dev/md2 mdadm: stopped /dev/md2 DMZ-07> mdadm --assemble --verbose --force /dev/md2 /dev/sda3 /dev/sdb3 /dev/sdc3 mdadm: looking for devices for /dev/md2 mdadm: /dev/sda3 is identified as a member of /dev/md2, slot 0. mdadm: /dev/sdb3 is identified as a member of /dev/md2, slot 1. mdadm: /dev/sdc3 is identified as a member of /dev/md2, slot 2. mdadm: clearing FAULTY flag for device 2 in /dev/md2 for /dev/sdc3 mdadm: added /dev/sdb3 to /dev/md2 as 1 mdadm: added /dev/sdc3 to /dev/md2 as 2 mdadm: no uptodate device for slot 3 of /dev/md2 mdadm: added /dev/sda3 to /dev/md2 as 0 mdadm: /dev/md2 has been started with 3 drives (out of 4). DMZ-07> DMZ-07> /proc/mdstat -ash: /proc/mdstat: Permission denied DMZ-07> cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md2 : active raid5 sda3[0] sdc3[2](E) sdb3[4] 8776632768 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUE_] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [4/4] [UUUU] md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3] 2490176 blocks [4/4] [UUUU] unused devices: <none> DMZ-07> fsck -ash: fsck: not found DMZ-07> e2fsck Usage: e2fsck [-panyrcdfvtDFV] [-b superblock] [-B blocksize] [-I inode_buffer_blocks] [-P process_inode_size] [-l|-L bad_blocks_file] [-C fd] [-j external_journal] [-E extended-options] device Emergency help: -p Automatic repair (no questions) -n Make no changes to the filesystem -y Assume "yes" to all questions -c Check for bad blocks and add them to the badblock list -f Force checking even if filesystem is marked clean -v Be verbose -b superblock Use alternative superblock -B blocksize Force blocksize when looking for superblock -j external_journal Set location of the external journal -l bad_blocks_file Add to badblocks list -L bad_blocks_file Set badblocks list DMZ-07> e2fsck -nvf Usage: e2fsck [-panyrcdfvtDFV] [-b superblock] [-B blocksize] [-I inode_buffer_blocks] [-P process_inode_size] [-l|-L bad_blocks_file] [-C fd] [-j external_journal] [-E extended-options] device Emergency help: -p Automatic repair (no questions) -n Make no changes to the filesystem -y Assume "yes" to all questions -c Check for bad blocks and add them to the badblock list -f Force checking even if filesystem is marked clean -v Be verbose -b superblock Use alternative superblock -B blocksize Force blocksize when looking for superblock -j external_journal Set location of the external journal -l bad_blocks_file Add to badblocks list -L bad_blocks_file Set badblocks list DMZ-07> e2fsck -nvf /dev/md2 e2fsck 1.42.6 (21-Sep-2012) Pass 1: Checking inodes, blocks, and sizes Enfait je viens de me rendre compte que la commande que j'ai utilisé n'est pas la bonne mais j'arrive pas à arrêter le premier test. J'ai donc lancé un autre test dans une autre fenêtre : DMZ-07> fsck. fsck.ext3 fsck.ext4 fsck.hfsplus DMZ-07> fsck. fsck.ext3 fsck.ext4 fsck.hfsplus DMZ-07> fsck.ext4 /dev/md2 e2fsck 1.42.6 (21-Sep-2012) 1.42.6-3776: is cleanly umounted, 422485/274272256 files, 1883956891/2194158192 blocks DMZ-07> -------------------------------------------------------- Quelqu'un sait comment on arrête e2fsck ? DMZ-07> e2fsck -nvf /dev/md2 e2fsck 1.42.6 (21-Sep-2012) Pass 1: Checking inodes, blocks, and sizes ^C^C^X^C^ (commande toujours en cours) ------------------------------------------ C'est bon l'annulation a bien été prise en compte. Par contre je fais quoi maintenant? ------------------------------------- Je biens de me rendre compte que j'avais fait le cat avant de faire le check disque donc je remet le résultat de maintenant DMZ-07> cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md2 : active raid5 sda3[0] sdc3[2](E) sdb3[4] 8776632768 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUE_] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [4/4] [UUUU] md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3] 2490176 blocks [4/4] [UUUU] unused devices: <none> DMZ-07> -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Donc pour toi il faudrait que je fasse les commandes que tu m'as donné et que je ne tienne pas compte de cet accès partiel alors? Donc on parle bien des commandes suivantes : mdadm --stop /dev/md2 mdadm --assemble --verbose --force /dev/sda3 /dev/sdb3 /dev/sdc3 /proc/mdstat puis fsck J'ai rien loupé? Pour la commande mdadm par contre c'est pas précisé dans celle que tu m'a pas envoyé "/dev/md2". C'est normal? Il faudra pas aussi que je passe par un unmount avant de faire le premier stop? ou il est implicite? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Petite précision, je me suis connecté avec winscp pour mieux voir et effectivement c'est bien ce que je disais, j'ai accès aux dossier qui étaient partagé sur le NAS sans problème. Concernant mon disque iSCSI je l'ai bien trouvé dans le dossier indiqué plus haut par contre il est en "brut", c'est à dire que c'est un gros fichier de 5To (la taille du disque que j'avais fait), mais bien sur comme ça, impossible de le monter et je suis quasiment certain que si j'essaye de copier le bloc ça va planter... Petite question, est-ce que si j'efface des données des partages classiques ça pourrais éventuellement améliorer la situation? (vu que le NAS était plein à 80% avant de planter) ---- Ca veut dire quoi les iSCSI sont en mode fichier? Que je peux le copier et l'exploiter par la suite si la copie (entière) se passe bien? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Dans l'ordre. Le "UUE_" Je trouve ça logique vu qu'actuellement il voit le dernier disque comme étant hors du RAID donc le _, et il voit le 3ème disque en erreur; d'ou le E. Les 2 premiers étant clean, RAS. J'me trompe? Pour les commandes, c'est fait! Aucune erreur par contre 2 choses! D'une part j'ai bien une liste de fichier qui apparait et ce sont bien mes fichiers mais pas tout. Mais bizarrement, avant de faire "mdadm --stop /dev/md2" je voyait déjà cette liste de fichier quand je faisais un "ls -l" sur un dossier, mais je sais plus lequel exactement... Quand je dis que je vois une liste de fichier c'est à dire que je vois les partages classiques qui étaient fait sur le RAID. On en arrive au 2ème truc, qui est que j'utilisais principalement un disque iSCSI. Mais mes principales données sont dessus. Quand j'ai listé les données du dossier volume1 j'ai vu qu'il y en avait un qui s'appelle "@iSCSITrg" (ça sonne bien) donc je suis allé dedans et j'ai trouvé "iSCSI_1_Extent_LUN-HDD_000" qui corresponds au nom de la target que j'avais fait. Par contre pour pouvoir la monter faut pas que je sorte du mode debug? Ou winscp sais monter ça? C'est ce qui m'a semblé aussi pour le superblock. Par contre comme j'ai déjà fais les commandes de gaetan, le volume est pas déjà monté justement? Les commandes que tu m'a donné sont pour corriger le superblock? -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Ok c'est noté. Ok pour moi. J''ai qu'un envie c'est de sauvegarder! ^^ Résultat de la commande : DMZ-07> cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md2 : active raid5 sda3[0] sdc3[2](E) sdb3[4] 8776632768 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUE_] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [4/4] [UUUU] md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3] 2490176 blocks [4/4] [UUUU] unused devices: <none> DMZ-07> -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
J'ai essayé de chercher à gauche à droite par rapport aux différents messages que j'ai eu et apparemment il faudrait que je reconstruise le "superblock" et que je vérifie le tout avec "fsck.ext4". Est-ce que vous approuvez? Vous pouvez me dire comment utiliser ces commandes si c'est le cas? Et du coup il faut que je redémonte le RAID? Actuellement le NAS est toujours avec la diode status orange clignotante et il ne réponds à rien d'autre qu'au SSH... ---------------------------------------- Au passage j'ai aussi tenté la carte "récupération en laboratoire" et j'ai contacté plusieurs boites françaises pour avoir un devis gratuit après leur avoir expliqué le problème. C'est... cher! Très cher même!!! Pour un RAID5 on est en gros entre 1500 et 3.000€ pour un particulier. C'est un petit prix spécial. Pour les sociétés il faut ajouter 20% voir plus si des contraintes de temps sont à prendre en compte. Il y en a juste 1 qui m'a proposé d'utiliser leur logiciel pour faire le taf chez moi dans un premier temps (si ça marche). Je préfère essayer dans un premier temps directement sur le NAS et voir après avec leur logiciel si ça n'aboutie. Ce qui est sur c'est qu'on ne m'y reprendra pas!!! Avec mes pauvres connexion internet précédente j'avais oublié le fait de prendre en compte le cloud pour des envois enTo mais maintenant que je suis fibré c'est tout à fait envisageable et je suis prêt à dégainer ma CB pour un abo hubic dès que (si) je remet la main sur mes DATAs! Tout ça avec votre aide bien sur. =) -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Bon! J'ai tout fait! Pour l'instant il réponds (sur l'interface web), le voyant status clignote en orange, le voyant pour le disque 3 est toujours orange mais s'est stabilisé en orange fixe. J'attends... Voici le résultat des commandes : DMZ-07> mdadm --stop /dev/md2 mdadm: failed to stop array /dev/md2: Device or resource busy Perhaps a running process, mounted filesystem or active volume group? DMZ-07> DMZ-07> DMZ-07> syno_poweroff_task -d DMZ-07> man syno_poweroff_task -ash: man: not found DMZ-07> DMZ-07> mdadm --stop /dev/md2 mdadm: stopped /dev/md2 DMZ-07> DMZ-07> mdadm --assemble --verbose /dev/md2 /dev/sda3 /dev/sdb3 /dev/sdc3 mdadm: looking for devices for /dev/md2 mdadm: /dev/sda3 is identified as a member of /dev/md2, slot 0. mdadm: /dev/sdb3 is identified as a member of /dev/md2, slot 1. mdadm: /dev/sdc3 is identified as a member of /dev/md2, slot 2. mdadm: device 2 in /dev/md2 has wrong state in superblock, but /dev/sdc3 seems ok mdadm: added /dev/sdb3 to /dev/md2 as 1 mdadm: added /dev/sdc3 to /dev/md2 as 2 mdadm: no uptodate device for slot 3 of /dev/md2 mdadm: added /dev/sda3 to /dev/md2 as 0 mdadm: /dev/md2 has been started with 3 drives (out of 4). DMZ-07> PS: Ou est-ce que j'peux avoir un descriptif de toutes ces commandes? Parcequ'il n'y a pas de man dans le syno et je trouve pas de gros manuel en ligne non plus... J'ajoute que j'ai fais un autre test juste pour voir si le message avait changé DMZ-07> cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md2 : active raid5 sda3[0] sdc3[2](E) sdb3[4] 8776632768 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUE_] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [4/4] [UUUU] md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3] 2490176 blocks [4/4] [UUUU] unused devices: <none> DMZ-07> Bon. J'ai toujours aucune réaction et le syno n'est joignable par aucun autre moyen que la fenetre SSH sur laquelle je suis. J'ai voulu voir s'il était en plein job donc j'ai fais un sfdisk et voici le résultat. (j'ai comme l'impression qu'il a planté... DMZ-07> sfdisk -l /dev/sda1 256 4980735 4980480 fd /dev/sda2 4980736 9175039 4194304 fd /dev/sda3 9437184 5860528064 5851090881 fd /dev/sdb1 256 4980735 4980480 fd /dev/sdb2 4980736 9175039 4194304 fd /dev/sdb3 9437184 5860528064 5851090881 fd /dev/sdc1 256 4980735 4980480 fd /dev/sdc2 4980736 9175039 4194304 fd /dev/sdc3 9437184 5860528064 5851090881 fd /dev/sdd1 256 4980735 4980480 fd /dev/sdd2 4980736 9175039 4194304 fd /dev/sdd3 9437184 5860528064 5851090881 fd /dev/md01 0 4980351 4980352 0 /dev/md11 0 4194175 4194176 0 /dev/md21 0 17553265535 17553265536 0 Error: /dev/zram0: unrecognised disk label get disk fail Error: /dev/zram1: unrecognised disk label get disk fail Error: The backup GPT table is not at the end of the disk, as it should be. This might mean that another operating system believes the disk is smaller. Fix, by moving the backup to the end (and removing the old backup)? Warning: Not all of the space available to /dev/synoboot appears to be used, you can fix the GPT to use all of the space (an extra 25600 blocks) or continue with the current setting? /dev/synoboot1 63 32129 32067 ef /dev/synoboot2 32130 224909 192780 ef DMZ-07> -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
C'est noté. Par contre avec quelle commande je dois le forcer? Parce-que j'ai vu plein de trucs différents et je ne sais pas vraiment laquelle est le plus adapté à mon cas... -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Bon, j'ai cherché un peu sur l'internet et j'ai vu que ça changeais rien cette ligne. Par contre quand j'ai voulu taper la première commande il m'a demandé une élévation de droit pour pouvoir le faire. Et quand j'ai voulu me mettre en root je me suis heurté au problème "su: must be suid to work properly" Internet aussi m'a bien aidé j'ai réussi à m'en débarrasser et maintenant je suis en root et j'ai tapé la commande mais j'ai le message suivant : DMZ-07> mdadm --stop /dev/md2 mdadm: failed to stop array /dev/md2: Device or resource busy Perhaps a running process, mounted filesystem or active volume group? J'ai trouvé des trucs pour "forcer" un démontage mais j'ai trouvé ça un peu délicat donc je préfère agir avec approbation... Et la commande lsof n'étant pas reconnu, je ne sais pas comment savoir/vérifier quel est le fichier qui est actuellement utilisé et bloque le démontage... PS: même après un reboot j'ai le même message d'erreur au passage. -
[Résolu] Dure fin de nuit... - RAID 5 HS sur Synology DS412+
JeanSimon a répondu à un(e) sujet de JeanSimon dans Sauvegarder et Restaurer
Désolé, j'ai oublié une ligne dans mon premier collage de résultat. Après le paragraphe md0 il y avait ça unused devices: <none> Est-ce que ça change quelque chose?