bruno78
-
Compteur de contenus
706 -
Inscription
-
Dernière visite
-
Jours gagnés
14
Tout ce qui a été posté par bruno78
-

SSD M2 pour NAS - Intérêt ?
bruno78 a répondu à un(e) sujet de boogiesyno dans Installation, Démarrage et Configuration
@niklos0 bonjour, la dernière analyse (Nov/2020) que j'avais lancée donne les résultats suivants : ce sont en très grandes majorité de petits fichiers.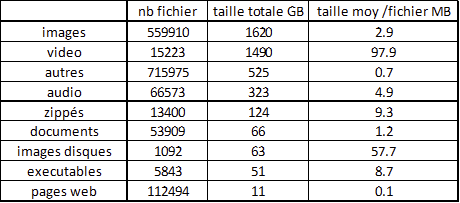
-
SSD M2 pour NAS - Intérêt ?
bruno78 a répondu à un(e) sujet de boogiesyno dans Installation, Démarrage et Configuration
Bonjour , expérience personnelle : je n'ai pas fait de vrai tests comparatifs chiffrés je suis en environnement mono utilisateur / perso mais : HyperBackup : (à volume de données à sauvegarder équivalent) sans cache SSD : backup vers C2 = env. 30 min avec cache SSD : backup vers C2 = env. 11 min WordPress : 4 installations WordPress (natives) avec le plugin WordFence. sans cache SSD : echec des Scan périodiques en timeout au bout de 3 heures (on peut rallonger la tempo, mais est-ce bien raisonnable ?) avec des taux d'utilisation des disques autour de 80%, avec ralentissement général du NAS. avec cache SSD : les scan périodiques sont exécutés en environ 20 à 40 minutes, sans impact sur la réactivité générale pendant ce temps. fluidité légèrement accrue de la réactivité de l'interface graphique Meilleure réactivité des dockers et VM (je n'ai pas d'éléments chiffrés) Cependant : fonctionnement sans problème pendant 12 mois et depuis 4 mois j'ai accumulé plusieurs problèmes de crash du NAS vraisemblablement dus à une défaillance matérielle de mes SSD NVME (2 * Samsung 970 EVO+ 250GB). Je les ai remplacés cette semaine par des WD Black 500GB. Je n'ai pas assez de recul pour me prononcer sur la fiabilité. -
Reverse-proxy ne fonctionne plus
bruno78 a répondu à un(e) sujet de Jules Perrelet dans Installation, Démarrage et Configuration
Bonjour, est-ce que tu as ce genre de notifications : "Système : Certaines pages Web ne peuvent plus fonctionner correctement" ?? -
@Jeff777 pour le PI, tu peux déjà prendre ça dans les input plugins ############################################################################### # INPUT PLUGINS # ############################################################################### # Read metrics about cpu usage [[inputs.cpu]] ## Whether to report per-cpu stats or not percpu = true ## Whether to report total system cpu stats or not totalcpu = true ## If true, collect raw CPU time metrics. collect_cpu_time = false ## If true, compute and report the sum of all non-idle CPU states. report_active = false # Read metrics about disk usage by mount point [[inputs.disk]] ## By default stats will be gathered for all mount points. ## Set mount_points will restrict the stats to only the specified mount points. # mount_points = ["/"] ## Ignore mount points by filesystem type. # ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"] # Read metrics about disk IO by device [[inputs.diskio]] ## By default, telegraf will gather stats for all devices including ## disk partitions. ## Setting devices will restrict the stats to the specified devices. # devices = ["sda", "sdb", "vd*"] ## Uncomment the following line if you need disk serial numbers. # skip_serial_number = false # ## On systems which support it, device metadata can be added in the form of ## tags. ## Currently only Linux is supported via udev properties. You can view ## available properties for a device by running: ## 'udevadm info -q property -n /dev/sda' ## Note: Most, but not all, udev properties can be accessed this way. Properties ## that are currently inaccessible include DEVTYPE, DEVNAME, and DEVPATH. # device_tags = ["ID_FS_TYPE", "ID_FS_USAGE"] # ## Using the same metadata source as device_tags, you can also customize the ## name of the device via templates. ## The 'name_templates' parameter is a list of templates to try and apply to ## the device. The template may contain variables in the form of '$PROPERTY' or ## '${PROPERTY}'. The first template which does not contain any variables not ## present for the device is used as the device name tag. ## The typical use case is for LVM volumes, to get the VG/LV name instead of ## the near-meaningless DM-0 name. # name_templates = ["$ID_FS_LABEL","$DM_VG_NAME/$DM_LV_NAME"] # Get kernel statistics from /proc/stat [[inputs.kernel]] # no configuration # Read metrics about memory usage [[inputs.mem]] # no configuration # Get the number of processes and group them by status [[inputs.processes]] # no configuration # Read metrics about swap memory usage [[inputs.swap]] # no configuration # Read metrics about system load & uptime [[inputs.system]] ## Uncomment to remove deprecated metrics. # fielddrop = ["uptime_format"]
-
@Jeff777 pour Portainer, je ne pratique pas, donc attendre l'avis de @.Shad. pour se connecter sur influxdb : (remplacer les user/mot de passe par les bons !!) se connecter sur le container : docker exec -it influxdb /bin/bash se logger sur influxdb : influxdb -username <admin> -password <"admin"> lister les databases : > show databases se connecter sur une database particulière : > use <database_name> lister les "measurements" présents : > show measurements puis tu peux lister une table : > select * from <measurement_name> root@influxdb:/# influx -username admin -password "admin" Connected to http://localhost:8086 version 1.8.4 InfluxDB shell version: 1.8.4 > show databases name: databases name ---- nas_telegraf_vps _internal pi_telegraf ovh_vps_telegraf fbx_telegraf_v8 sl_stats nas_telegraf sl_ip_stats nas_speedtest pi4_telegraf > use pi4_telegraf Using database pi4_telegraf > show measurements name: measurements name ---- cpu disk diskio docker docker_container_blkio docker_container_cpu docker_container_health docker_container_mem docker_container_net docker_container_status ifTable ipNetToMediaTable kernel mem net processes rpi4B_model rpi4B_temp snmp.rpi4 storageTable swap system tcpConnTable > et pour finir tu peux lister par exemple un measurement : > select * from <measurement_name> .... mais ca peut être volumineux ...
-
@Jeff777, As-tu essayé de te connecter sur le docker influxdb et vérifié ce qui est populé dans la base "raspi_telegraf" ? On voit à la fois des données telegraf arriver (semble t'il) , et des requetes Grafana. Donc en toute logique ..... Soit la requete grafana n'est pas bonne, soit les données ne sont pas celles attendues => d'où l'idée de vérifier sur influxdb ce qui est réellement enregistré dans la db. Tous mes docker telegraf, influxdb, grafana sont en mode bridge, sans pb, certains colocalisés sur la meme machine, d'autres distants .
-
@Jeff777 bonjour, pour le log du container telegraf du RPi, as-tu positionné les variables correspondantes dans le fichier de configuration de telegraf ? ## Log at debug level. debug = true ## Log only error level messages. quiet = false ## Log target controls the destination for logs and can be one of "file", ## "stderr" or, on Windows, "eventlog". When set to "file", the output file ## is determined by the "logfile" setting. logtarget = "file" ## Name of the file to be logged to when using the "file" logtarget. If set to ## the empty string then logs are written to stderr. logfile = ""
-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@Jeff777 alors voilà : sous DSM7, pas de "synoservicecfg" ensuite, je me suis aperçu qu'à chaque tentative de réparation, il me sortait également une alarme "certaines pages web ne peuvent pas fonctionner" (alors que les sites hebergés fonctionnent) du coup je me suis dit qu'il y avait peut-être un lien entre AudioStation et Web Station ???? donc arrêt propre de WebStation (incl. Apache 2.2 et Apache 2.4) re-installation de AudioStation depuis centre de paquets DSM => OK redémarrage WebStation , Apache 2.2 et Apache 2.4. et cela semble fonctionner correctement, aussi bien l'appli Desktop que via DSAudio Android. J'avoue que je ne m'explique pas le lien entre les 2 ... -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@EVOTk, @Jeff777, même ainsi, ça ne passe pas ..... root@ds918blam:/var/packages/AudioStation# synopkg install AudioStation-x86_64-7.0.0-5058.spk {"error":{"code":0},"results":[{"action":"install","beta":true,"betaIncoming":true,"error":{"code":276,"description":"failed to acquire postinst worker","worker_msg":[]},"finished":true,"installReboot":false,"installing":true,"language":"enu","last_stage":"postreplace","package":"AudioStation","packageName":"Audio Station","pid":22602,"scripts":[{"code":0,"message":"","type":"preinst"},{"code":0,"message":"","type":"postinst"}],"spk":"AudioStation-x86_64-7.0.0-5058.spk","stage":"install_failed","status":"stop","success":false,"username":""}],"success":false} -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@EVOTk @Jeff777, merci pour vos retours, je m'en occupe dans la journée. Cdt, bruno78 -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
bonjour @Jeff777, peux-tu stp m'expliquer la marche à suivre pour installer manuellement en ssh un paquet qui refuse la réparation ? (Audio Station en l’occurrence) ? Merci d'avance -
[TUTO] Certificat Let's Encrypt avec acme.sh & api Ovh en Docker (DSM6/7) (Update 07/09/22)
bruno78 a répondu à un(e) sujet de Einsteinium dans Tutoriels
@Einsteinium j'ai relancé la commande de déploiement à la main ("docker exec Acme sh -c "acme.sh --deploy -d 'mydomain.com' --deploy-hook synology_dsm"") est tout est rentré dans l'ordre. Peut-être (c'est même probable) ne l'avais-je pas exécutée lors de la mise en place initiale comme indiqué (point 3.B.3 du Tuto) ... cdt, Bruno78 -
[TUTO] Certificat Let's Encrypt avec acme.sh & api Ovh en Docker (DSM6/7) (Update 07/09/22)
bruno78 a répondu à un(e) sujet de Einsteinium dans Tutoriels
@Einsteinium, Il n'est pas exclu que je sois sur la version n-1 du Tuto ... Je regarde . Bruno78 -
[TUTO] Certificat Let's Encrypt avec acme.sh & api Ovh en Docker (DSM6/7) (Update 07/09/22)
bruno78 a répondu à un(e) sujet de Einsteinium dans Tutoriels
@oracle7 bonjour, oui mais j'avais cru comprendre que c'était réglé .... . Bruno78 -
[TUTO] Certificat Let's Encrypt avec acme.sh & api Ovh en Docker (DSM6/7) (Update 07/09/22)
bruno78 a répondu à un(e) sujet de Einsteinium dans Tutoriels
@Einsteinium bonjour, j'ai eu cette semaine les renouvellements automatiques des mes 3 domaines : 2 domaines purement dédiés hébergement (des sites wordpress dans des vhost), et en dernier le domaine principal de mon Syno et de tous ses services. Chacun à 2 jours d'intervalle, ça permet de voir plus clair. Résultats : domaine hébergement (www.ndd1.tld1) => renouvellement auto OK, rien à ajouter ! domaine hébergement (www.ndd2.tld2) => echec lors de la première tentative ("forbidden call") je ne touche à rien, ok le lendemain lors de l'essai suivant. PS : c'est tombé en plein pendant l'épisode incendie chez OVH, est-ce que leurs services n'étaient pas un peu perturbés ??? ....) domaine principal de mon Syno, avec tous les services associés renouvellement OK et certificat bien déployé automatiquement sous DSM. A priori on se dit tout va bien ... mais en regardant => c'est toujours l'ancien certificat qui semble être utilisé !! alors qu'il n'apparait plus sous DSM ... ???? Purge du cache navigateur n'y change rien. Le certificat est bien déployé dans DSM : Mais le certificat utilisé est toujours l'ancien ... ??? Et au niveau du Log je ne vous mets que la fin, mais bon c'est OK : [Sun Mar 14 00:41:09 UTC 2021] Generate form POST request [Sun Mar 14 00:41:09 UTC 2021] Upload certificate to the Synology DSM [Sun Mar 14 00:41:09 UTC 2021] POST [Sun Mar 14 00:41:09 UTC 2021] _post_url='http://172.17.0.1:5000/webapi/entry.cgi?api=SYNO.Core.Certificate&method=import&version=1&SynoToken=KscmmODGz6Yiw&_sid=N3WJNnGN0hMgpuc9uopTLqPTsFInzannauvVY9TPyAcbV47DkDXRoGAnxYaeSHiwAwxPWNrTlMs5iPSwnaotbU' [Sun Mar 14 00:41:09 UTC 2021] _CURL='curl --silent --dump-header /acme.sh/http.header -L -g ' [Sun Mar 14 00:41:56 UTC 2021] _ret='0' [Sun Mar 14 00:41:56 UTC 2021] http services were restarted [Sun Mar 14 00:41:56 UTC 2021] Success [Sun Mar 14 00:41:56 UTC 2021] Return code: 0 [Sun Mar 14 00:41:56 UTC 2021] _error_level='2' [Sun Mar 14 00:41:56 UTC 2021] _set_level='2' [Sun Mar 14 00:41:56 UTC 2021] The NOTIFY_HOOK is empty, just return. [Sun Mar 14 00:41:56 UTC 2021] ===End cron=== Peut-être dois-je simplement re-importer le certificat à la main ? Cdt, Bruno78

-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
Bonsoir @maxou56 alors si je me penche sur les données des 2 SSD comme tu l'indiques : pour le Cache 1 et pour le cache 2 Or : ces 2 SSD ont toujours été montés ensembles donc la différence de "Power On Hours" = 28h ??!! Si je prends le graffe de température du SSD cache2 que j'avais noté à -1 il "manque" environ 12 heures. Je n'ai pas trouvé d'autre comportement de ce genre sur les 3 derniers mois (je ne garde les stats que 3 mois). Mais pas impossible que ce se soit déjà produit sans que l'on incrimine le SSD .... L'hypothèse d'une panne aléatoire du SSD prend t'elle forme d'après vous ? Merci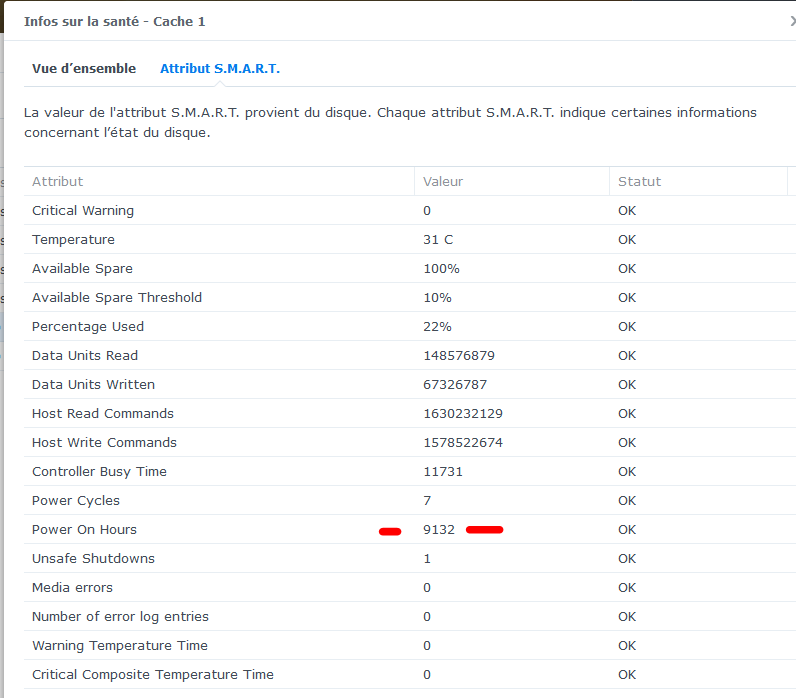
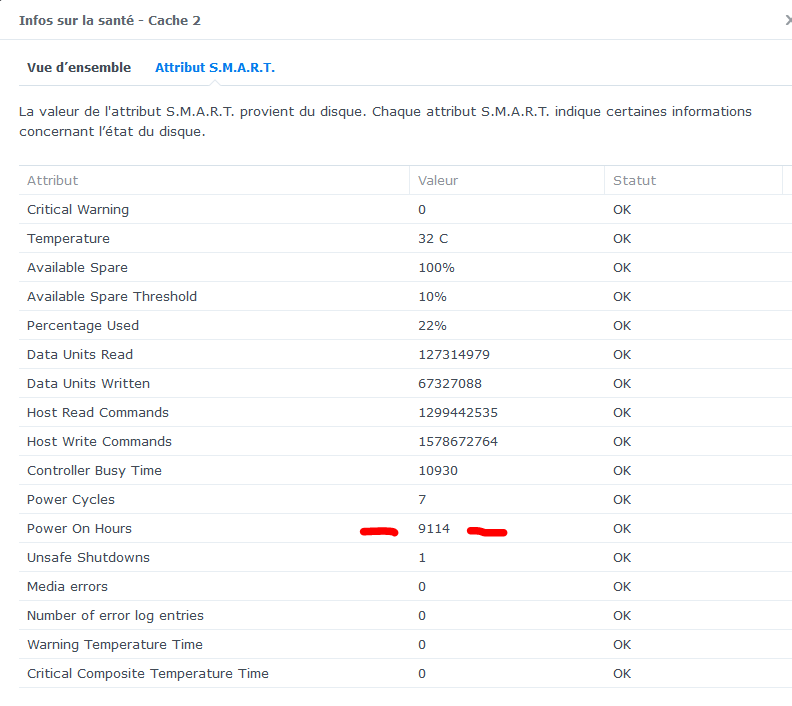
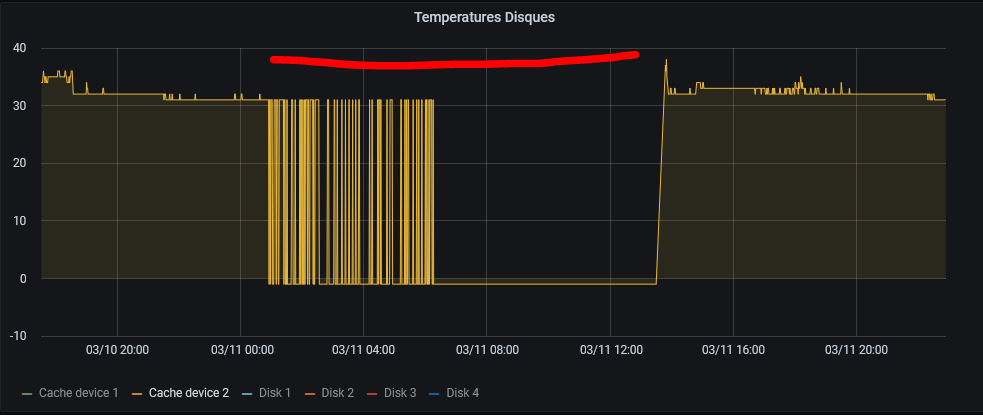
-
@oracle7 d'un côté c'est plutôt bon signe, .... mais du coup ça n'explique pas où est ton problème ....
-
OK. Je n'ai pas trop de temps ces jours ci, mais je vais regarder.
-
Bonjour @Denisra76Frog, je n'aime pas trop faire les choses complètement en aveugle, mais je vais jeter un coup d’œil. Peux-tu me donner le lien où l'on parle de cette connexion ? Bruno78
-
@oracle7 bonjour, puis-je faire une suggestion ? As-tu essayer de lancer un "snmpwalk" depuis une console ssh vers un élément de la MIB ? Cela peut permettre de voir des messages d'erreur que l'on ne voit pas sinon. D'abord depuis une console ssh du NAS, puis depuis une console ssh dans le docker lui-même.
-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
ok donc je vais enlever une barette de 8Go et garder la seconde 8Go en service. Merci -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@EVOTk et du coup, pour repasser à 8Go, il faut absolument faire du 4Go+4Go, ou une seule barette 8Go est supportée ? -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
Pour être précis, c'est ça que je recois régulièrement : Or à ce moment là, la mémoire dite "libre" tombe de 495Mo à 211Mo. Mais ce n'est pas comme si il ne restait pas 5.4Go de buffer dans lesquels aller puiser ? J'avoue que je ne comprends pas très bien comment la mémoire est gérée ....
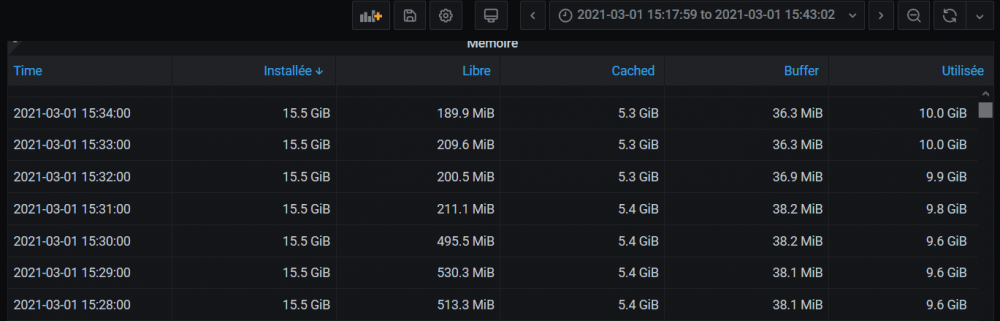
-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@.Shad. @EVOTk, difficile de pointer du doigt à coup sûr l'origine. J'ai rétabli le cache SSD R/W, et je vais passer de 16 à 8 Go de RAM, pour voir si cela change quelque chose au comportement du NAS. => voir si il y a des dégradations visibles de performance. Le fait est que de temps en temps j'ai une alerte "mémoire insuffisante", alors que loin de là !! Je vais voir si ce message apparait encore avec 8Go de RAM. -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@Jeff777 @.Shad. en fait 2 pistes : soit effectivement un pb avec un SSD, soit, et le support Syno m'en a remis une couche, un effet de bord d'avoir 16Go de RAM .... pas officiellement supporté par Syno.