bruno78
-
Compteur de contenus
706 -
Inscription
-
Dernière visite
-
Jours gagnés
14
Tout ce qui a été posté par bruno78
-

[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
Voila Voila, c'est reconfiguré !! Bon tout semble fonctionner correctement 🙂 Maintenant 2 chantiers : mettre un syslog externe au NAS mettre en docker les hébergements web .... et surveiller le comportement du cache ssd ...... -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@Jeff777 Le support a débloqué l'installation des paquets Apache en relançant le syslog .... bon, ok ..... N'empêche que mon webstation ne sait toujours pas où il habite, donc je désinstalle et re-installe ... et je refais les maj. pour les vhosts wordpress .... que je vais mettre en container parce qu'à chaque fois qu'il y a un problème ou une maj, les configs modifiées nginx et consort passent à la trappe ..... Il est donc urgent de se rendre indépendant ! -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
@Jeff777 merci pour ton retour, pour le moment je laisse le support Syno prendre la main dessus et regarder (c'est encours). C'est le but même de la Beta, voir si il y a du grain à moudre ou pas. Je ne suis pas à 1 heure prêt (heureusement) et à partir du moment où je n'ai pas perdu de données ... bah ça va déjà mieux . J'avais déjà eu quelque chose de similaire, il avait fallu désinstaller complètement Webstation (incl. les paquets Apache et en ne conservant pas les paramètres), reinstaller et reconfigurer les vhost ... 1 petite heure de boulot. Si ils trouvent le pourquoi du comment de la non réparation des paquets Apache, je vous tiens au courant. -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
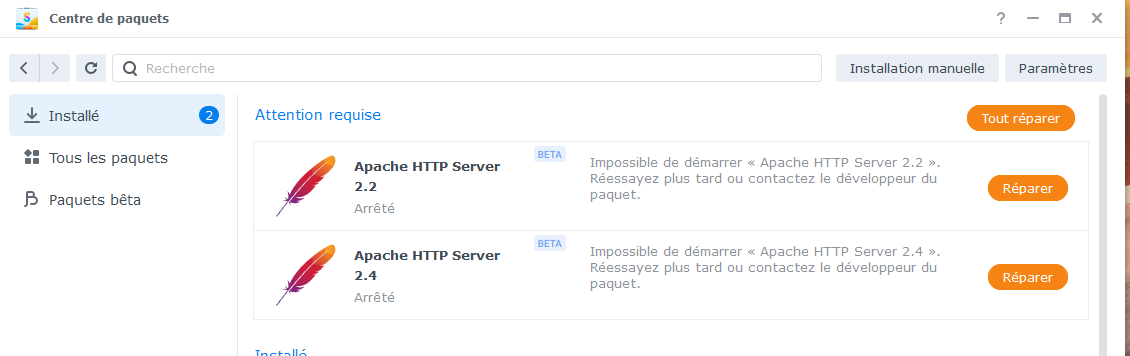
Les paquets qui me donnent du mal, et qui sont vraisemblablement la cause des problèmes WebStation, sont les 2 paquets Apache, qui refusent de se réparer !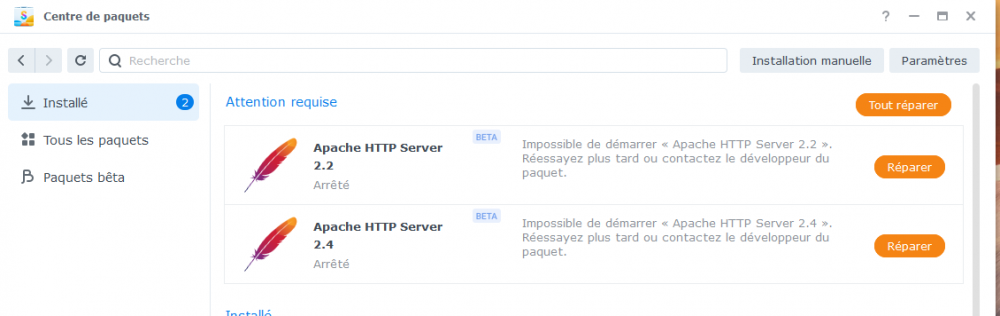
-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
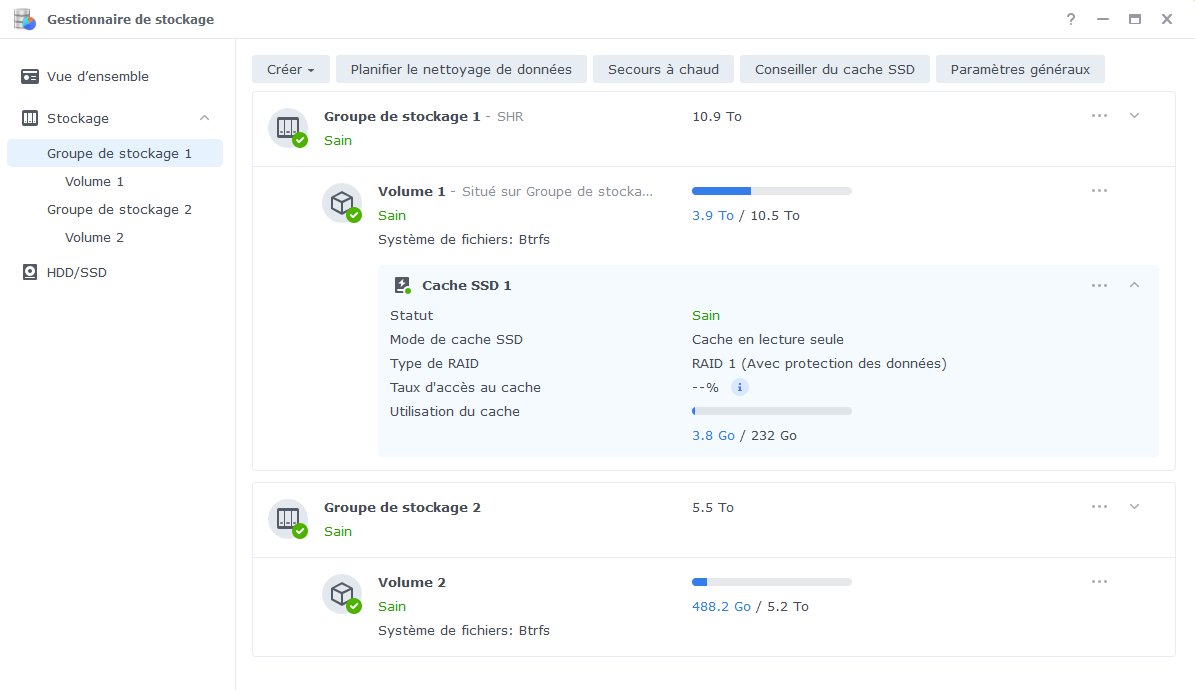
@Mic13710 oui tout à fait. D'où un œil constant sur les sauvegardes :-). En l’occurrence, même si il a bien redémarré (à Webstation prêt !) je crains plutôt sur ce coup là une petite défaillance matérielle sur l'un des 2 caches SSD NVME. A surveiller de très prêt. -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
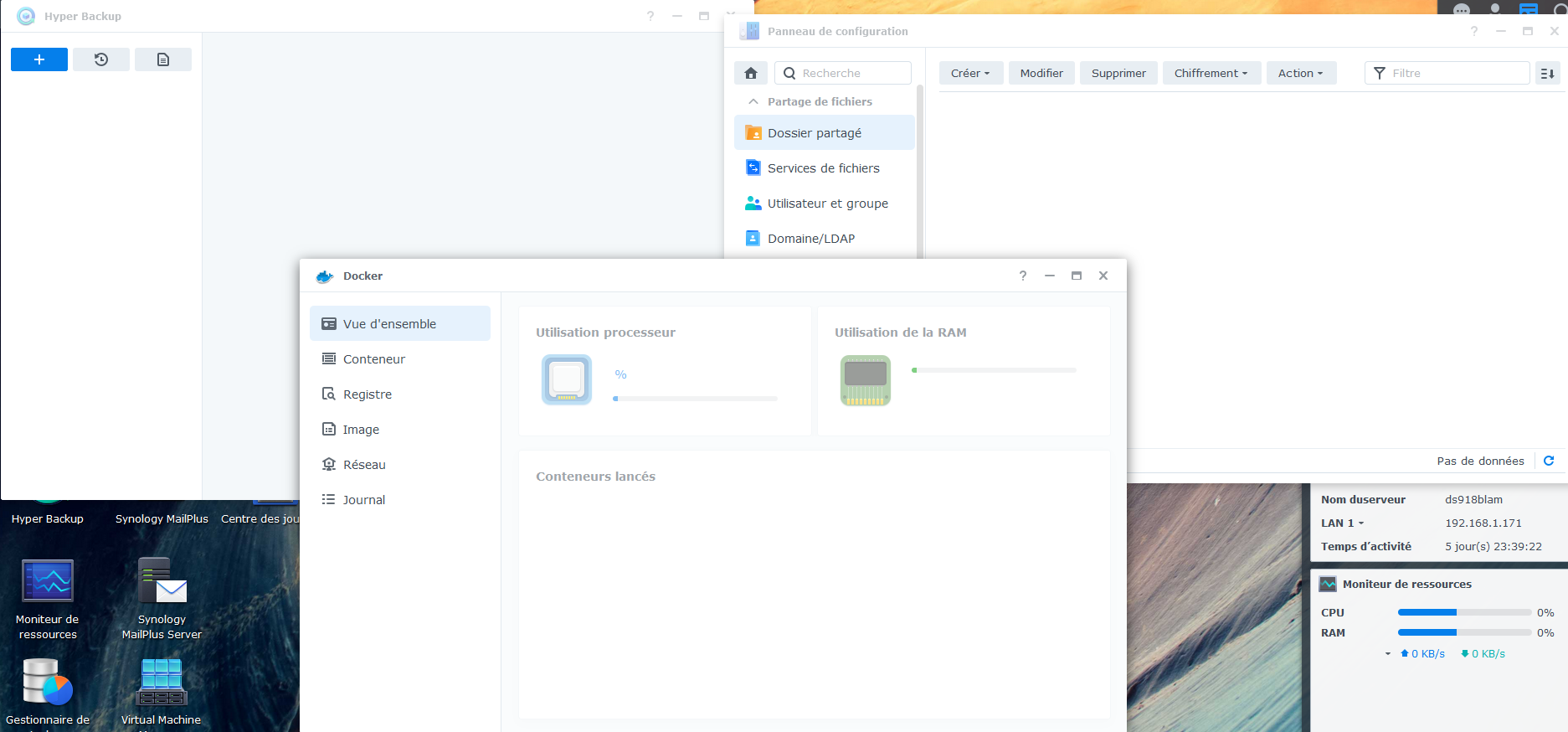
Bon, après reset au bouton POWER (meme le support me le conseillait comme seule solution), retour à la vie : A priori pas de perte de données, mais vérifications à venir. Par contre reverse proxy, webstation, .... c'est n'importe quoi ... Les journaux systèmes ont été rincés. Par contre les logs des dockers confirment qu'il était bien vivant ... J'ai du travail de vérification pour la journée... Cdt, bruno78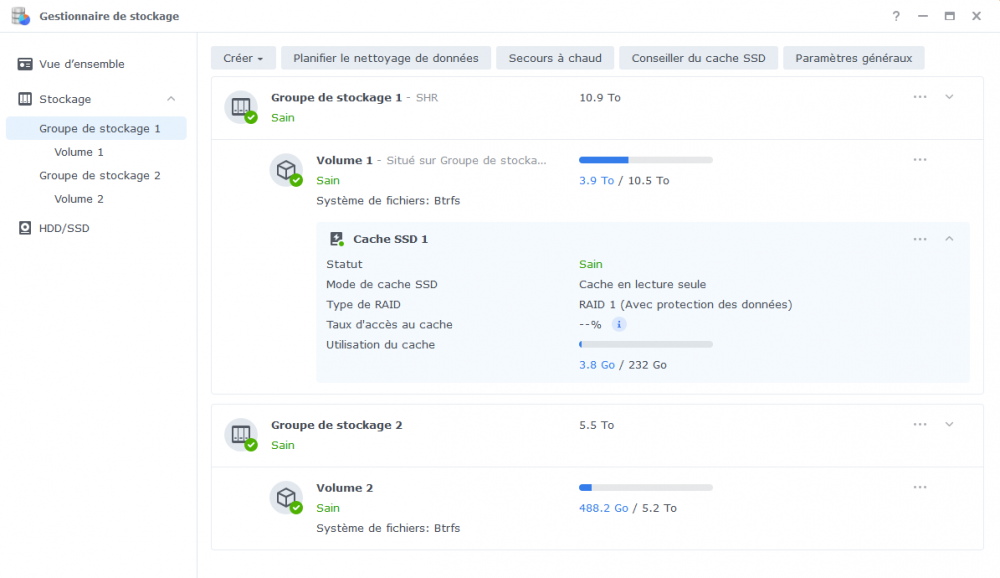
-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
Bon ben quand faut y aller ... PS : courage pour ceux qui sont sur OVH STBG .... -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
bonjour @.Shad., non, malheureusement plus accès à rien, ni via DSM ni via ssh. Le plus étonnant c'est qu'il y a toujours une certaine activité, certains dockers répondent (dont telegraf !). Le bouton de reset n'est pas pris en compte, il y a de l'activité sur les HDD, le cpu tourne, pas de saturation mémoire . Pas de led d'anomalie .... Et précisemment, comme il y a de l'activité, un arrêt brutal ne me tente pas trop car risque élevé de corruption. Le seul point positif, c'est que j'ai des sauvegardes .... Pour le support, je n'ai pas grand chose à leur fournir du coup .... ( à l'avenir, j'archiverai les logs en dehors du NAS ....)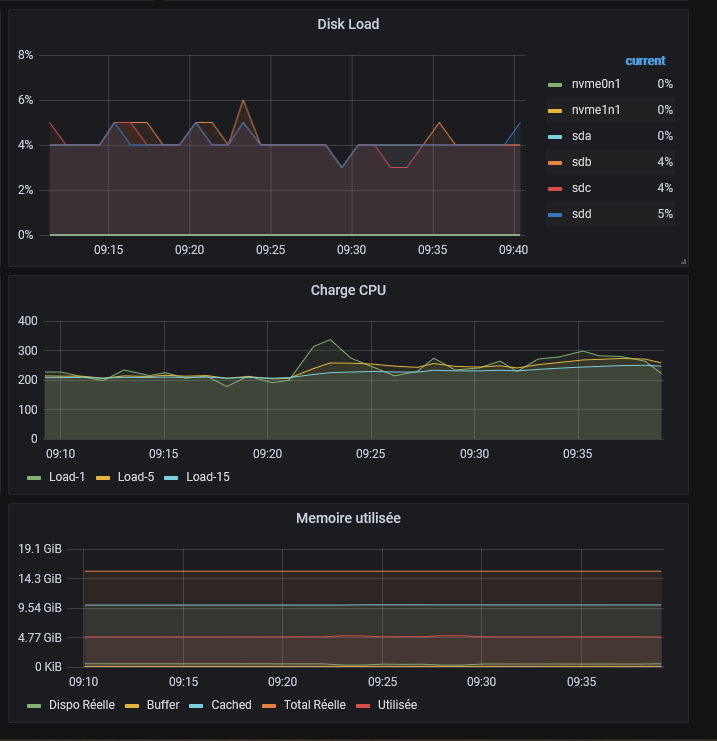
-
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
Suite : NAS invisible depuis le synology assistant connection au DSM désormais impossible bouton arrière RESET inoperant pourtant un certain nombre de services fonctionnent semble t'il !! J'attends un peu avant un arrêt brutal , voir si vous avez des suggestions, mais moi j'ai fait le tour de ce que je pouvais faire "proprement" -
[Terminé] cette nuit Plantage du DS918+ / DSM ....
bruno78 a répondu à un(e) sujet de bruno78 dans Installation, Démarrage et Configuration
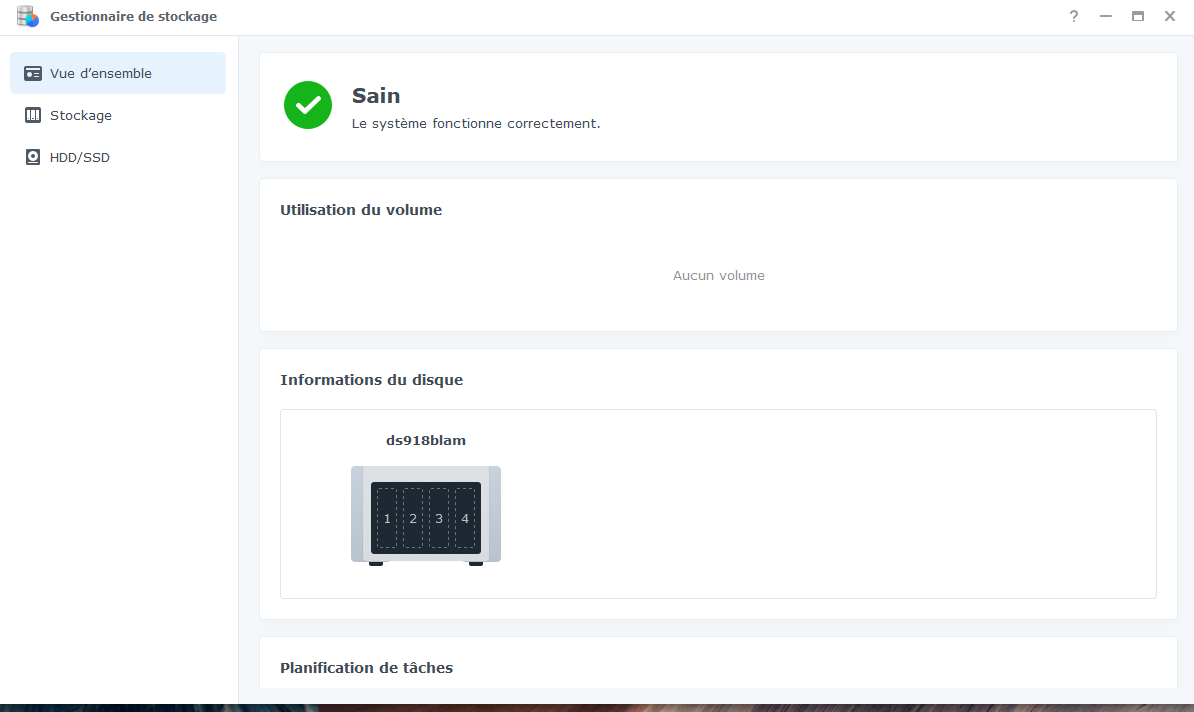
par ailleurs, les 2 SSD ont disparu la surveillance des disques : avant : maintenant :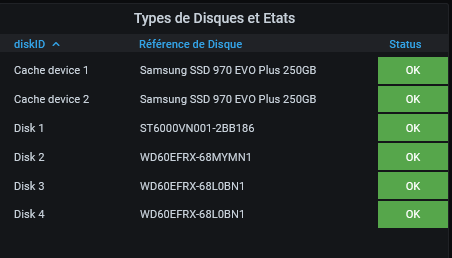
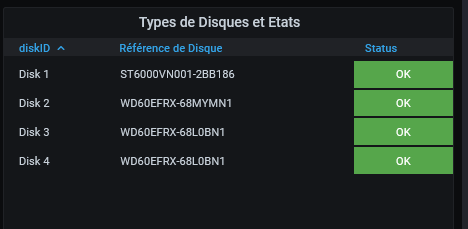
-
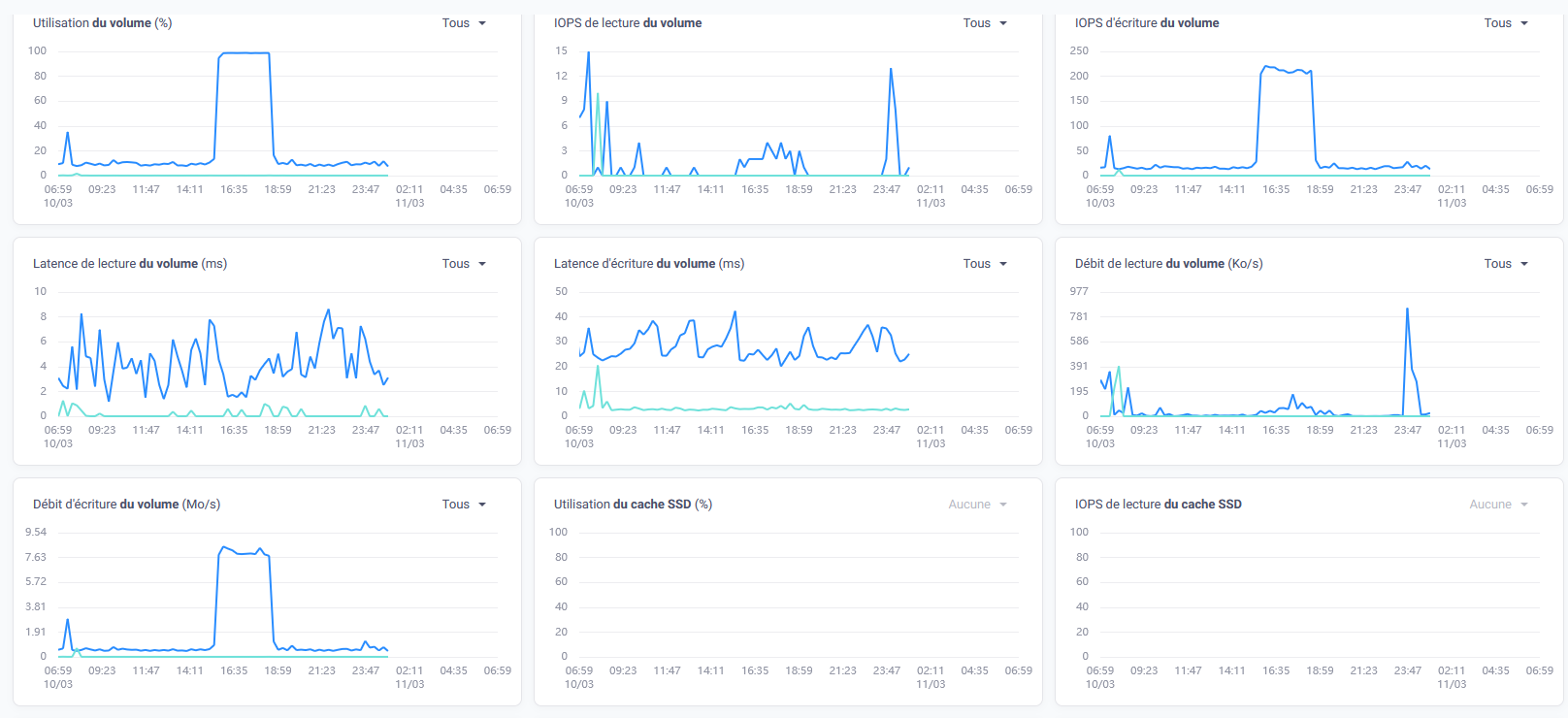
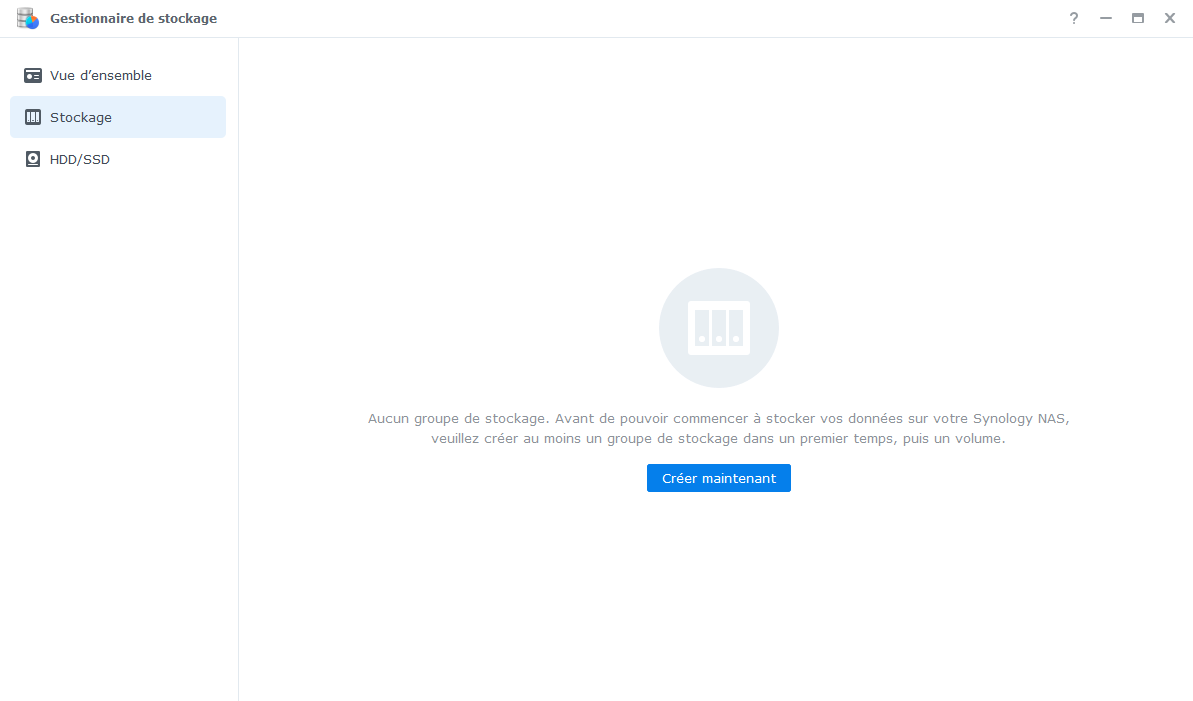
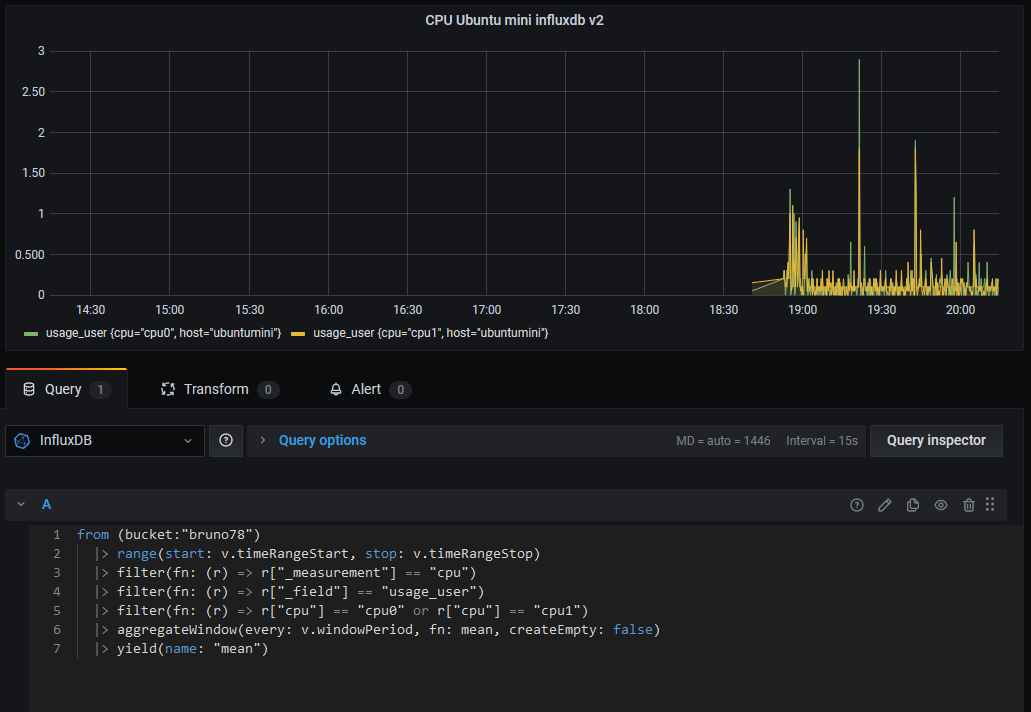
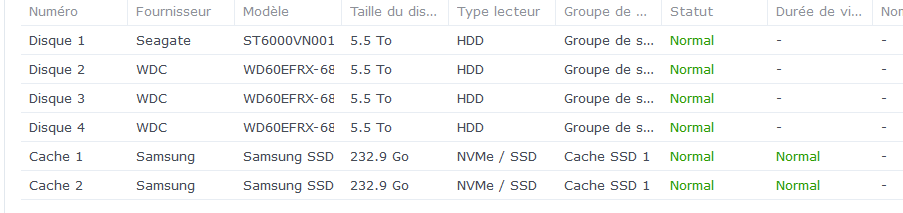
Bonjour, tout allait plutôt bien dans le meilleur des mondes, jusqu'à ce matin. Le DS918 sous DSM7 semble avoir eu des vapeurs cette nuit. A la connexion, le bureau est réinitialisé, comme neuf !. Les applis sont là mais ne répondent pas forcement. Connexion ssh impossible. Bien que l'écran soit vide, les dockers semblent continuer à tourner (dixit grafana), même si pas forcement accessibles depuis le réseau. Si on regarde Active Insight, il n'y a plus de données remontées depuis cette nuit. La je suis un peu perdu ... Merci pour les pistes que vous pourriez me donner. PS : j'ai un doute sur l'état du cache SSD ..... pb matériel ? Cdt, Bruno78 Côté gestionnaire de stockage, ce n'est pas encourageant : Quant au monitoring grafana, il me donne ceci pour les températures de disques, ce qui me laisse entrevoir une panne matérielle sur l'un des caches SSD ? bruno78
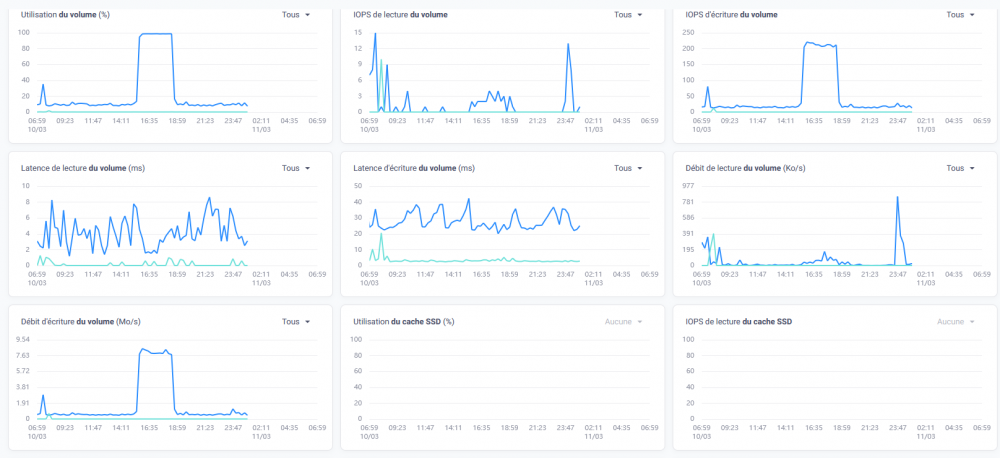
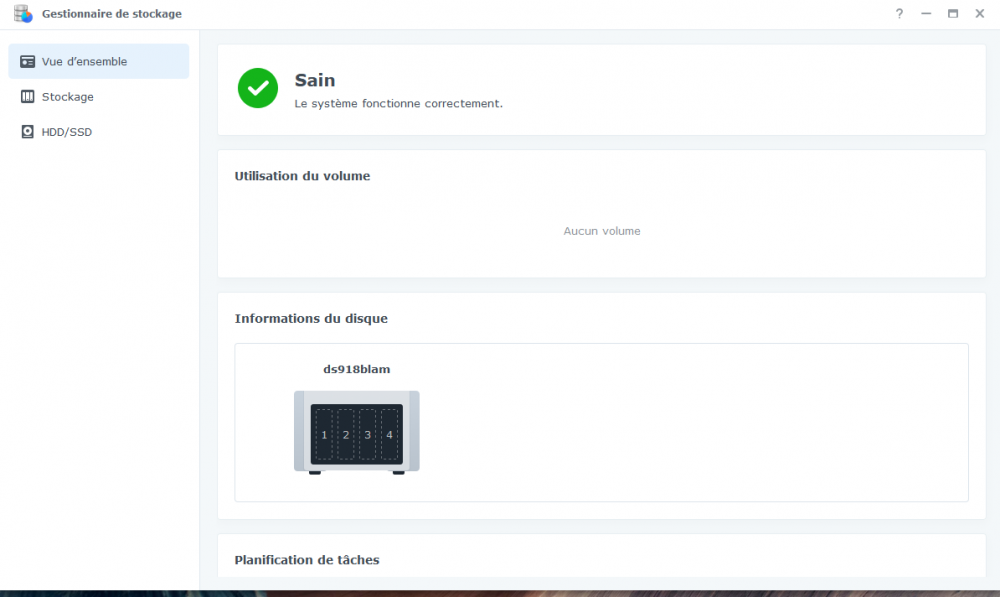
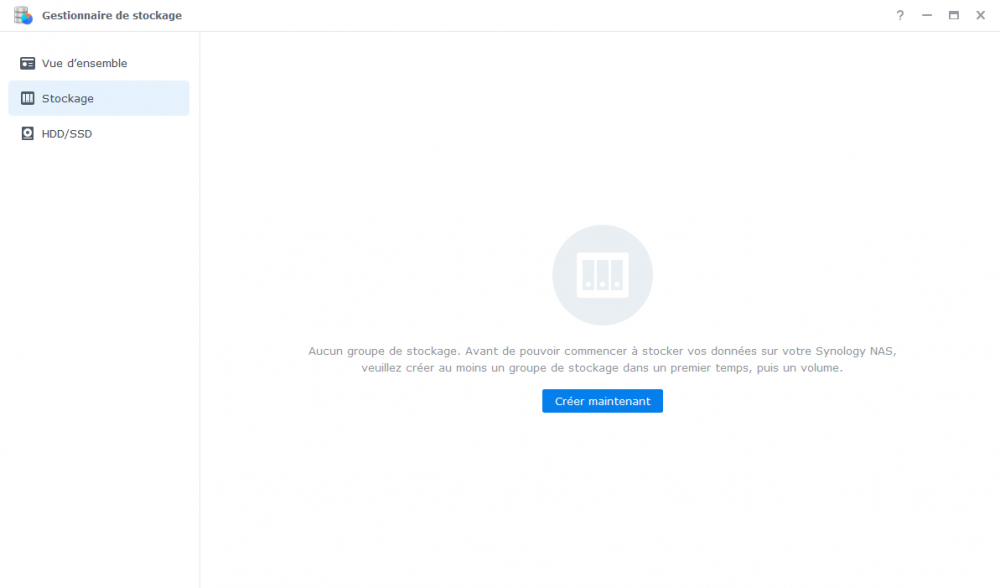
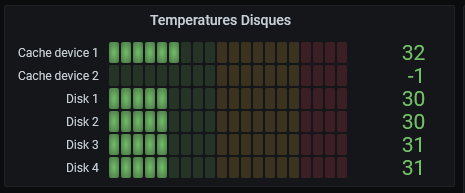
-
Bonsoir @Denisra76Frog, Bienvenue parmi nous. content de voir que je ne suis pas seul sur Influxv2 ! Je suis en train d'essayer d'y convertir tous mes dashboards. Et certains posent plus de problèmes que d'autres .... (j'ai entre autres des problèmes avec les variables dans les dashboards !) Pour la 4G je ne sais pas ... Si l'API ne dit rien, .... . Et comme je n'ai qu'une Révolution, donc sans 4G ... N'hésites pas à faire un tour par la case présentation 🙂 Bruno78
-
@Jeff777 oui je me souviens bien de ta problématique. 2 solutions pour utiliser directement le python : soit un container sur mesure (que tu as déjà testé mais tu veux garder la possibilité de mise à jour), soit se passer de docker et utiliser directement le Python du DSM , sachant que sur DSM7 le python est intégré de base, mais il faudra quand même rajouter des modules spécifiques .... je ne sais pas alors ce qui se passera lors d'une mise à jour DSM ? Pour le moment je suis reparti sur une solution docker et image personnalisée (et je butte sur un stupide problème de crontab dans le container .... mais ce n'est pas le sujet). Si je n'y arrive pas ou si trop contraignant, j'essaierai quand même la solution d'utiliser le python du DSM.
-
@.Shad. effectivement, ce sont les 2 axes repérés. Je me suis d'abord dit : "on peut se passer de grafana". Presque .. il manque des fonctionnalités de customisation des graphes, plugins, .... . Mais c'est vrai que cela fait hésiter. Si ils font un effort de ce côté là, on devrait pouvoir se passer de Grafana. Mais si on a d'autres sources (Loki par exemple), je ne sais pas comment influxdb2 va le gérer ... ou pas. Et il y a les "tasks". mais là je n'ai pas regardé du tout. Pour l'instant je galère (mais ce n'est pas avec Influxdb) avec le dashboard Freebox, que j'ai essaie de faire passer directement du Python vers Influxdb, sans passer par telegraf ....
-
@MilesTEG1, voir les dashboards en début de discussion page 1. Ils n'évoluent pas. Influxdb est le maillon du milieu : les sources (telegraf ou autres) sont les mêmes, et au niveau de l'affichage c'est le même grafana. Pour le moment je recrée les dashboards à l'identique et j'apprends à me servir d'Influxdb2. Pour le moment, outre le langage de script différent, j'ai rencontré quelques problèmes de typage de données : int() versus float() versus boolean() versus string(), alors que la source telegraf est strictement la même. De plus, le constructeur de requêtes est sur l'interface GUI d'influxdb2, pas encore sur grafana, ce qui oblige à faire un peu de gymnastique entre les 2. Apparemment, côté grafana/influxdb docker, ils vont sortir un moyen de migrer de influxv1 vers influxv2 .... ça risque d'être l'usine à gaz. Dans une deuxième phase, et c'est là le plus intéressant, je regarderai ce que l'on peur faire de plus avec de nouvelles fonctionnalités d’influxdbv2 ... mais ça ce sera après 🙂. bruno78
-
@Diabolomagic sur ce coup là je ne peux pas t'aider .... pas de SRM à la maison .....
-
C'est bon, ça marche en Docker 🙂 avec InfluxDB_v2. Mais encore beaucoup de points à explorer .....
-
@.Shad., @oracle7, @MilesTEG1, après une journée de lutte acharnée, je viens de monter un premier graphe via telegraf > Influxdb V2 > grafana ... Un bon conseil, ne soyez pas trop pressés d'y passer. Quelle galère ! Bon on sent que la peinture n'est pas sèche. côté influxdbv2, je n'ai pas réussi en docker à le faire causer avec telegraf. Donc j'ai fait une installation sur une VM ubuntu. côté grafana, ben comment dire : pour construire les graphes, il faut passer par le scripting "Flux". Aie Aie Aie . Tout à réapprendre ! Donc pour le moment c'est bien prise de tête ! Côté Docker ce n'est pas prêt, pour grafana le support de "Flux" n'est annoncé qu'en Beta, .... ca risque de bouger encore. A noter par contre qu'il y a un constructeur de requete "Flux" sur Influxdb_v2 lui-même. Bonne soirée. Bruno78
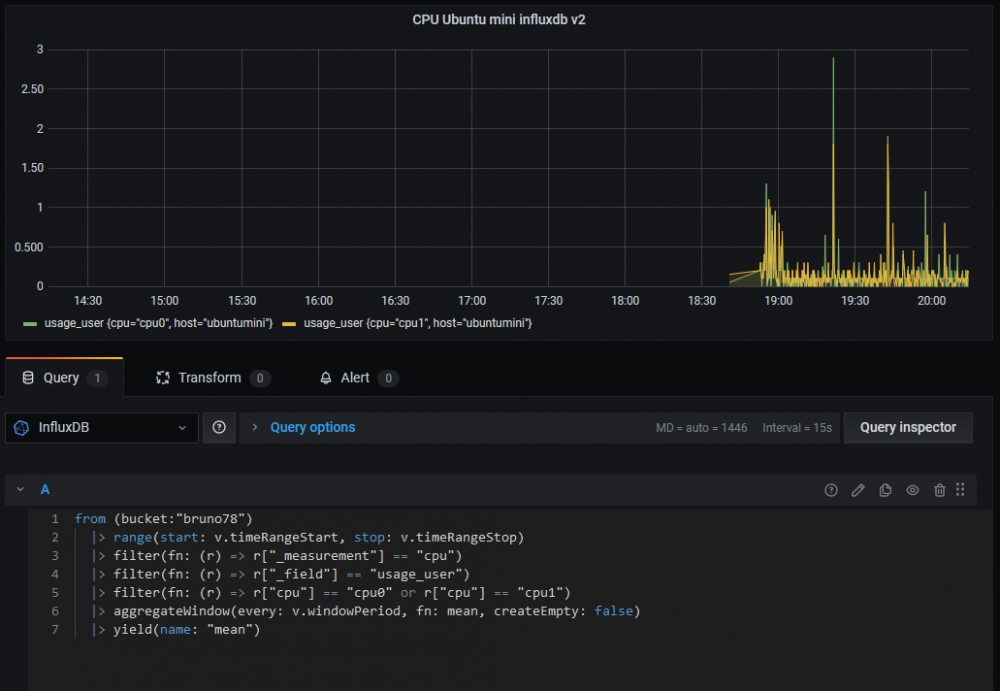
-
@MilesTEG1 😮 je vais me refaire un café ...... !!!!
-
@oracle7@.Shad., j'ai commencé à regarder le sujet .... c'est du lourd ! J'en suis "simplement" à l'authentification, .... et au final je tombe sur If you already have Telegraf installed on your system, make sure it's up to date. You will need version 1.9.2 or higher. Or en docker, la dernière version de telegraf est la 1.17.3 .... Donc pour le moment c'est un peu bloqué .... Bruno78
-
@PPJP Mille excuses, je n'ai pas fait attention que tu avais en fait déjà réalisé les modifications !! Donc un grand merci à toi. Bruno78
-
@PPJP merci d'avoir passé un peu de temps à décortiquer l'affaire, echo >> $tmp1 : je vais le rajouter listes feodotracker : je vais ajouter tes remarques en entête de fichier, et par défaut ne charger que la liste agressive listes mariushosting : je vais recontacter l'auteur pour voir ce qui est possible ou pas. Si pas possible, ton idée est intéressante et doit pouvoir se mettre en place facilement. Je regarde. autres améliorations : compactage de code et amélioration de la vitesse: suis pas forcement suffisamment compétent ... (et ne suis pas l'auteur initial du code). Quelles seraient les pistes d'amélioration d'après toi ? infos finales à améliorer : ça doit pouvoir se faire ... bruno78
-
@MilesTEG1 content que tu ais trouvé le problème ..... c'est aussi une des raisons pour lesquelles je ne fais pas mise à jour automatique des dockers .... (j'ai eu des soucis il y a quelques mois avec une maj. Telegraf ....) Mon plus gros soucis avec InfluxDB, c'est la consommation mémoire ... Si la V2 améliore ce point, j'irai peut-être voir ... ??
-
@MilesTEG1 upgrade DSM : de quelle version à quelle version stp ?
-
@MilesTEG1 je suppose que ce problème est apparu au moment de la mise en œuvre de ta solution DNS / Adguard ? => as-tu moyen de faire un bref retour en arrière, juste pour voir ?